理解 RACK 的原理和实现
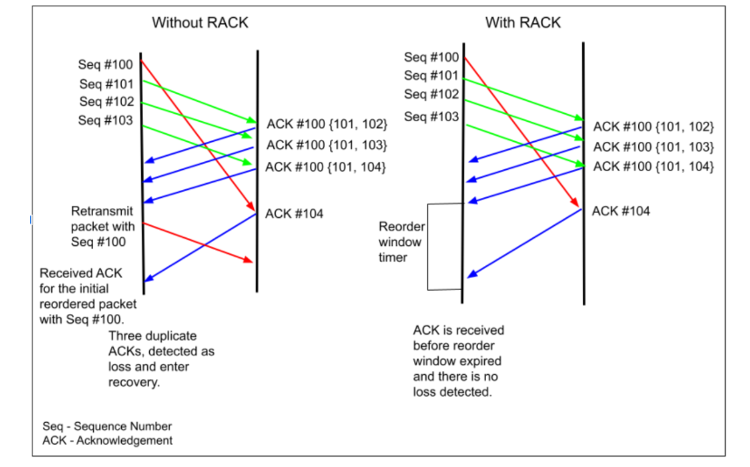
在 RACK 之前, TCP 的快速恢复采用对 DupACK 进行计数作为进入条件, 当计数超过 DupThresh 时, 触发快速恢复流程.
但这种方法对 application-limited 的应用来说并不可靠, 因为这类应用不会持续发送数据, 而 DupACK 需要报文触发才能生成,
这就导致一旦报文丢失, DupACK 不会增加, 最终发送方触发 RTO 超时重传流程, 而非快速恢复.
可以把 RTO 超时重传理解为是”急刹车”, 快速恢复则是”点踩刹车”,前者代价高,后者代价低
RACK 是一种基于时间的丢包侦测(loss detect)算法. 这里的重点是时间, 而不是数量
这就摆脱了对报文发送量的依赖, 从而适用于 application-limited 的应用.
从原理上看, RACK 会为每个发送的报文(包括重传)保留了一个虚拟计时器, 当虚拟计时器到期时,
RACK 将报文标记为 lost, 触发快速恢复流程.
从实现上看, RACK 是记录了每个报文的”最后”一次发送时间。每当收到一个 ACK 时, 就根据最新的 RTT 测量值,
调整尚未被确认报文的过期时间, 一旦过期, 就触发快速恢复流程。
RACK 算法描述
发送报文
发送(重传)报文时, 记录其发送时间
RACK_transmit_new_data(Segment):
Segment.xmit_ts = Now()
Segment.lost = FALSE
RACK_retransmit_data(Segment):
Segment.retransmitted = TRUE
Segment.xmit_ts = Now()
Segment.lost = FALSE
收到 ACK
Step1. 根据该 ack 报文进行 RTT 测量, 并将估算的 windowed min RTT 保存到 RACK.min_RTT.
Step2. 刷新 RACK state
首先刷新变量 RACK.segment、RACK.xmit_ts、RACK.ack_ts,RACK.end_seq、RACK.rtt.
其中RACK.segment为被 ACK(或SACK)的报文中最后发送(包括重传)的那一个 (发送时间上的最新, 不一定是序号上的最后)
RACK.xmit_ts为RACK.segment的发送时间戳,RACK.end_seq为RACK.segment的结束序号,RACK.ack_ts为RACK.segment被应答的事件戳
RACK.rtt为用最新被ACK(或SACK)的报文计算出的 RTT.
注意, RACK.rtt每次收到 ACK 都会刷新, 但RACK.segment和其相关的另外三个却不一定.
当报文在网络中未发生重排序时, RACK.rtt = RACK.ack_ts - RACK.xmit_ts
当报文在网络中发生重排序时, RACK.rtt > RACK.ack_ts - RACK.xmit_ts
从 ack 报文中提取 ACKed 和 SACKed 信息之后, 这些信息对应的报文会被标记为 delivered
当收到一个对已重传报文的 ACK 时, 需要格外小心, 因此此时重传可能是 spurious 的 (ACK 实际是对之前首传报文的应答)
此时用报文的发送时间再计算 RTT 就不太合理 (因为报文时间在重传时被刷新过)
SACK 用了一些办法来过滤这种情况:
- 如果启用 Timestamp 选项, 则我们可以根据 ACK 报文的 TSecr 清楚地分辨该 ACK 是对哪个报文的应答
- 如果未启用 Timestamp 选项, RACK 也忽略计算出的 RTT 小于 min RTT 的情形 (此时大概率是 spurious ACK)
以上过程用伪代码表示如下:
RACK_sent_after(t1, seq1, t2, seq2):
If t1 > t2:
Return true
Else if t1 == t2 AND seq1 > seq2:
Return true
Else:
Return false
RACK_update():
按发送时间从旧到新,遍历每个被 ACK 的报文 (包括被新 SACK 的)
in ascending order of Segment.xmit_ts:
rtt = Now() - Segment.xmit_ts
If Segment.retransmitted is TRUE:
如果该 ACK 应答的非该重传报文, 则忽略计算 (否则计算的 RTT 会很小)
If ACK.ts_option.echo_reply < Segment.xmit_ts:
Continue
If rtt < RACK.min_rtt:
Continue
RACK.rtt = rtt
If RACK_sent_after(Segment.xmit_ts, Segment.end_seq
RACK.xmit_ts, RACK.end_seq):
RACK.xmit_ts = Segment.xmit_ts
RACK.end_seq = Segment.end_seq
Step3. 识别重排序(reordering)
这一步比较简单, SACK 会造成报文序列上出现 Gap (可能是 loss, 也可能是 reordering).
而如果报文序列上 Gap 被填充上, 且这段 Gap 表示的报文未被重传, 则说明是 reordering, 而不是 loss
这段逻辑用伪代码表示如下, 特别注意只有”未被重传”的包填充了 Gap 才能用来决定发生了 reordering,
已重传的包, 不管有没有填充, 都不会确认 reordering.
RACK_detect_reordering():
in ascending order of Segment.end_seq:
If Segment.end_seq > RACK.fack:
RACK.fack = Segment.end_seq
Else if Segment.end_seq < RACK.fack AND
Segment.retransmitted is FALSE:
RACK.reordering_seen = TRUE
Step4. 更新 RACK reordering 窗口
RACK reordering 表示”一个时间范围”, 可以将其理解为 RACK 对 reordering 的忍受程度
在算法里, 这个窗口值表示为 RACK.reo_wnd, 它的值初始为 0, 且在进入快速恢复或者RTO恢复时都会重置为 0.
而当 RACK.reordering_seen 为 TRUE 时, RACK.reo_wnd 会设置为 RACK.min_RTT/4
这个值是估计的, 如果设置的比较小, 就可能出现虽然发生的是 reordering, 但 RACK 已经将其识别为 loss, 然后触发快速恢复重传.
此时, RACK.reo_wnd重置为 0, RACK 之后进行 Step3 识别 reordering 时, 就比较尴尬了, 由于这些报文都被重传过, 因此不能用其确定是否 reordering.
为了解决这个问题, SACK 应该将RACK.reo_wnd设置为RACK.min_RTT/4乘以一个倍数, 倍数的值为这一轮过程中收到 DSACK 的数量.
其意义是, 如果发生上面的问题,则会出现 DSACK, 证明 RACK 的RACK.reo_wnd取小了.
这段算法用伪代码表示为:
RACK_update_reo_wnd():
/* DSACK-based reordering window adaptation */
If RACK.dsack_round is not None AND
SND.UNA >= RACK.dsack_round:
RACK.dsack_round = None
/* Grow the reordering window per round that sees DSACK.
Reset the window after 16 DSACK-free recoveries */
If RACK.dsack_round is None AND
any DSACK option is present on latest received ACK:
RACK.dsack_round = SND.NXT
RACK.reo_wnd_mult += 1
RACK.reo_wnd_persist = 16
Else if exiting Fast or RTO recovery:
RACK.reo_wnd_persist -= 1
If RACK.reo_wnd_persist <= 0:
RACK.reo_wnd_mult = 1
If RACK.reordering_seen is FALSE:
If in Fast or RTO recovery:
Return 0
Else if RACK.segs_sacked >= DupThresh:
Return 0
Return min(RACK.reo_wnd_mult * RACK.min_RTT / 4, SRTT)
Step5. 丢包识别
RACK 会’拷打’ 所有已发送但尚未被 SACK 的报文, 如果它们同时满足以下两个条件, RACK 就将其标记为 lost
条件1: RACK.xmit_ts >= Segment.xmit_ts
条件2: RACK.xmit_ts - Segment.xmit_ts + (now - RACK.ack_ts) >= RACK.reo_wnd
条件2变形: now >= Segment.xmit_ts + RACK.reo_wnd + (RACK.ack_ts - RACK.xmit_ts)
条件1表示已经有后发送的报文被送达了, 而先发送的 Segment 还没有, 即后发先至.
根据条件2的变形, 结合 Step2 中 RACK.rtt >= RACK.ack_ts - RACK.xmit_ts
更加严格的条件就是
now >= Segment.xmit_ts + RACK.reo_wnd + `RACK.rtt`
再变形后
Segment.xmit_ts + RACK.rtt + RACK.reo_wnd - now <= 0
等式左边表示 Segment 在被 RACK 判别为 lost 之前的剩余时间(remaining)
RACK 算法建议使用一个定时器来定时, 取值为这些报文中 remaining 的最大值, 一旦定时器超时, 就将这个报文标记为 loss
之所以取最大值, 我觉得是为了效率考虑, 比如假设几个报文的 remaining 分别为 1.0s、1.1s、1.2s、1.3s. 此时将定时器设置为 1.3s,
则当定时器超时时, 如果这些报文还都没到, 则 RACK 可以一下子标记这几个报文为 lost
用伪代码表示, 就是
RACK_detect_loss():
timeout = 0
RACK.reo_wnd = RACK_update_reo_wnd()
For each segment, Segment, not acknowledged yet:
If RACK_sent_after(RACK.xmit_ts, RACK.end_seq,
Segment.xmit_ts, Segment.end_seq):
remaining = Segment.xmit_ts + RACK.rtt +
RACK.reo_wnd - Now()
If remaining <= 0:
Segment.lost = TRUE
Segment.xmit_ts = INFINITE_TS
Else:
timeout = max(remaining, timeout)
Return timeout
RACK_detect_loss_and_arm_timer():
timeout = RACK_detect_loss()
If timeout != 0
Arm the RACK timer to call
RACK_detect_loss_and_arm_timer() after timeout
RACK 内核实现
内核使用 sysctl 的 tcp_recovery 控制 RACK 行为. 也可通过 /proc/sys/net/ipv4/tcp_recovery 查看或设置, 默认值是 0x1
其取值是一个 bitmap, 其中 bit0 是 RACK 总开关, bit1 表示是否使用固定的 reordering 窗口, 也就是不受 DSACK 影响, bit2 表示是否关闭 DUPACK 数量的判断.
RACK: 0x1 enables the RACK loss detection for fast detection of lost
retransmissions and tail drops. It also subsumes and disables
RFC6675 recovery for SACK connections.
RACK: 0x2 makes RACK's reordering window static (min_rtt/4).
RACK: 0x4 disables RACK's DUPACK threshold heuristic
在 tcp sock 结构中, 内嵌了一个 tcp_rack 结构用于保存 RACK 的变量.
struct tcp_rack {
u64 mstamp; /* (Re)sent time of the skb */
u32 rtt_us; /* Associated RTT */
u32 end_seq; /* Ending TCP sequence of the skb */
u32 last_delivered; /* tp->delivered at last reo_wnd adj*/
u8 reo_wnd_steps; /* Allowed reordering window */
#define TCP_RACK_RECOVERY_THRESH 16
u8 reo_wnd_persist:5, /* No. of recovery since last adj */
dsack_seen:1, /* Whether DSACK seen after last adj */
advanced:1; /* mstamp advanced since last lost marking */
} rack;
当收到 ack 报文时, 首先解析其 SACK block, 如果发现它是 dubious ack, 则进入是否快速重传的判断
tcp_ack()
|
|-- tcp_sacktag_write_queue()
|
|-- if (tcp_ack_is_dubious(...))
|
|-- tcp_fastretrans_alert(...)
接下来, 会进入丢包识别, 然后进入 RACK 的处理. 重点关注 tcp_rack_detect_loss(), 其中会进行丢包识别
tcp_fastretrans_alert(...)
|
|-- tcp_identify_packet_loss(...)
|
|-- tcp_rack_mark_lost(...)
|
|-- tcp_rack_detect_loss(sk, &timeout);
|-- if (timeout)
|-- inet_csk_reset_xmit_timer(...)
tcp_rack_detect_loss()里, 首先计算 reording window. 再逐个拷打 tp->tsorted_sent_queue 上的报文,
注意,这个报文是按发送(重传)时间为顺序组织的, 这一点与重传队列按序号不同.
遍历时, 会逐个计算这些报文的剩余时间, 如果为负数, 就将其标记为 lost, 随后重传.
如果为正, 则找到这些报文中最大的 remaining, 将其作为最终的 timeout
tcp_rack_detect_loss(...)
|
|-- reo_wnd = tcp_rack_reo_wnd(sk)
|
|-- list_for_each_entry_safe(skb,..,&tp->tsorted_sent_queue,..)
|
|-- remaining = tcp_rack_skb_timeout(tp, skb, reo_wnd)
|-- if (remaining <= 0)
|-- tcp_mark_skb_lost(sk, skb)
|-- else
|-- *reo_timeout = max_t(u32, *reo_timeout, remaining)
实验
这里使用 packetdrill 脚本进行实验. 首先打开tcp_sack和tcp_recovery,
然后通过调整客户端的发送时间, 让 RTT 大约为 400ms. 这样min_rtt/4 约为 100ms
然后发送3个报文, 其中第二个报文丢失. 这样 RACK 会计算其超时时间为约 100ms , 100ms 后标记其 lost, 然后重传
0 `sysctl -q net.ipv4.tcp_sack=1`
0 `sysctl -q net.ipv4.tcp_recovery=1`
+0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
// 3-way handshake
+0 < S 0:0(0) win 32792 <mss 1000,sackOK,nop,nop,nop,wscale 7>
+0 > S. 0:0(0) ack 1 win 64240 <mss 1460,nop,nop,sackOK,nop,wscale 7>
//0.100 > S. 0:0(0) ack 1 <mss 1460,nop,nop,sackOK,nop,wscale 6>
+.4 < . 1:1(0) ack 1 win 257
+0 accept(3, ..., ...) = 4
// Write extra data segments.
+0 write(4, ..., 1000) = 1000
+0 > P. 1:1001(1000) ack 1
+0 write(4, ..., 1000) = 1000
+0 > P. 1001:2001(1000) ack 1
+0 write(4, ..., 1000) = 1000
+0 > P. 2001:3001(1000) ack 1
// 1 normal ack
+0.4 < . 1:1(0) ack 1001 win 257 <sack 2001:3001, nop, nop>
+0 > P. 1001:2001(1000) ack 1
+0.4 < . 1:1(0) ack 3001 win 257
抓包结果如下:

而如果将脚本开头的 tcp_recovery设置为0, 抓包将变成, 从图中可见, 第二个包大约 800ms 才发生了重传!
