XDP 接收报文实践
现代网卡能接收处理报文的极限通常会超过单个 CPU 能能力, 此时具有硬件 RSS 功能的网卡来对接收到的流量进行分流, 以将负载分发给不同的 CPU,
然而, 如果网卡不具有硬件 RSS 功能或者流量不符合 RSS 支持的类型 (比如我们想根据报文的非常规字段设计自定义的 CPU 分发规则) 时, 就需要另想办法.
这里, eXpress Data Path(XDP) 就是一个可选方案, 我们可以利用 XDP 实现可编程的 RSS, 以及其他更多功能….
XDP 的基本原理是在报文接收方向, 到达协议栈前对报文进行判决(judgement),报文根据结果执行后续动作(action),
这些动作包括: XDP_ABORTED \ XDP_DROP \ XDP_PASS \ XDP_TX \ XDP_REDIRECT
XDP_ABORTED \ XDP_DROP 表示报文将会被直接丢弃;
XDP_PASS 表示报文将被正常进入内核协议栈;
XDP_TX 表示该报文从收到的网卡原路发送回去(hairpin);
XDP_REDIRECT 表示将报文将重定向到新的目标。这里的目标可以是 other CPU \ other NIC \ an AFXDP socket
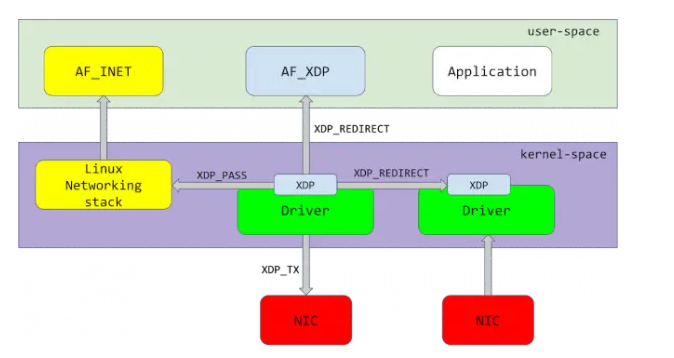
下面我们分别阐述这几类 action 的运用场景
XDP_ABORTED \ XDP_DROP
这两类动作表示主机拒绝该报文, 将收到的报文丢弃掉(这两者的区别仅在于是否触发 tracepoint 事件).
如果我们认为一些符合某些特征的流量是恶意攻击流量, 我们就可以在报文进行内核协议栈前就丢弃他们.
比如我们不想一个网卡收到UDP流量, 我们可以按以下方式编写 eBPF 程序, 拒绝掉这些流量.
int xdp_prog_drop_all_UDP(struct xdp_md *ctx)
{
void *data_end = (void *)(long)ctx->data_end; void *data = (void *)(long)ctx->data;
struct ethhdr *eth = data; u64 nh_off; u32 ipproto = 0;
nh_off = sizeof(*eth); /* ETH_HLEN == 14 */
if (data + nh_off > data_end) /*
return XDP_ABORTED;
if (eth->h_proto == htons(ETH_P_IP))
ipproto = parse_ipv4(data, nh_off, data_end);
if (ipproto == IPPROTO_UDP)
return XDP_DROP;
return XDP_PASS;
}
XDP_PASS
XDP_PASS 应该是作为绝大部分 XDP eBPF 程序的默认动作, 它将 XDP eBPF 程序不关心的报文送到内核协议栈, 该怎么处理就怎么处理.
因此编写 eBPF 程序时, 我们可以将其作为 action 的初始化值, 最后返回可能改变也可能不变的 action.
int xdp_prog_XXXX(struct xdp_md *ctx)
{
int action = XDP_PASS;
...(some logic may change 'action')...
return action;
}
XDP_TX
XDP_TX 表示该报文从收到的网卡原路发送回去(hairpin). 可以将此时的 eBPF 程序想像成一面镜子, 对感兴趣的流量进行反射.
实践中, 我们可以利用此特性实现业务报文快速应答, 这样一来, 就不必运行一个单独的用户进程。
比如, 如果收到报文满足一定的格式(长度\特征), 我们就可以对报文进行一些内容(报文头和payload)修改后, 利用 XDP_TX 发送回去
以下例子来自 https://github.com/xdp-project/xdp-tutorial/blob/master/packet03-redirecting/xdp_prog_kern.c
SEC("xdp_icmp_echo")
int xdp_icmp_echo_func(struct xdp_md *ctx)
{
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
struct hdr_cursor nh;
struct ethhdr *eth;
int eth_type;
int ip_type;
int icmp_type;
struct iphdr *iphdr;
struct ipv6hdr *ipv6hdr;
__u16 echo_reply, old_csum;
struct icmphdr_common *icmphdr;
struct icmphdr_common icmphdr_old;
__u32 action = XDP_PASS;
/* These keep track of the next header type and iterator pointer */
nh.pos = data;
/* Parse Ethernet and IP/IPv6 headers */
eth_type = parse_ethhdr(&nh, data_end, ð);
if (eth_type == bpf_htons(ETH_P_IP)) {
ip_type = parse_iphdr(&nh, data_end, &iphdr);
if (ip_type != IPPROTO_ICMP)
goto out;
} else if (eth_type == bpf_htons(ETH_P_IPV6)) {
ip_type = parse_ip6hdr(&nh, data_end, &ipv6hdr);
if (ip_type != IPPROTO_ICMPV6)
goto out;
} else {
goto out;
}
/*
* We are using a special parser here which returns a stucture
* containing the "protocol-independent" part of an ICMP or ICMPv6
* header. For purposes of this Assignment we are not interested in
* the rest of the structure.
*/
icmp_type = parse_icmphdr_common(&nh, data_end, &icmphdr);
if (eth_type == bpf_htons(ETH_P_IP) && icmp_type == ICMP_ECHO) {
/* Swap IP source and destination */
swap_src_dst_ipv4(iphdr);
echo_reply = ICMP_ECHOREPLY;
} else if (eth_type == bpf_htons(ETH_P_IPV6)
&& icmp_type == ICMPV6_ECHO_REQUEST) {
/* Swap IPv6 source and destination */
swap_src_dst_ipv6(ipv6hdr);
echo_reply = ICMPV6_ECHO_REPLY;
} else {
goto out;
}
/* Swap Ethernet source and destination */
swap_src_dst_mac(eth);
/* Patch the packet and update the checksum.*/
old_csum = icmphdr->cksum;
icmphdr->cksum = 0;
icmphdr_old = *icmphdr;
icmphdr->type = echo_reply;
icmphdr->cksum = icmp_checksum_diff(~old_csum, icmphdr, &icmphdr_old);
action = XDP_TX;
out:
return xdp_stats_record_action(ctx, action);
}
XDP_REDIRECT
XDP_REDIRECT 是 XDP action 中最复杂的一种, 因为它有多个重定向目标.
other CPU
如果是将报文重定向到其他 CPU, 这就有点像软件 RSS, 将报文重定向到其他 CPU 的协议栈中处理.
比如我们根据L4协议类型将报文分发到不同的 CPU
完整例子见: https://github.com/xdp-project/xdp-tools/blob/master/xdp-bench/xdp_redirect_cpumap.c
int cpumap_l4_proto(struct xdp_md *ctx)
{
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
__u32 key = bpf_get_smp_processor_id();
struct ethhdr *eth = data;
__u8 ip_proto = IPPROTO_UDP;
struct datarec *rec;
__u16 eth_proto = 0;
__u64 l3_offset = 0;
__u32 cpu_dest = 0;
__u32 *cpu_lookup;
__u32 cpu_idx = 0;
rec = bpf_map_lookup_elem(&rx_cnt, &key);
if (!rec)
return XDP_PASS;
NO_TEAR_INC(rec->processed);
if (!(parse_eth(eth, data_end, ð_proto, &l3_offset)))
return XDP_PASS; /* Just skip */
/* Extract L4 protocol */
switch (eth_proto) {
case ETH_P_IP:
ip_proto = get_proto_ipv4(ctx, l3_offset);
break;
case ETH_P_IPV6:
ip_proto = get_proto_ipv6(ctx, l3_offset);
break;
case ETH_P_ARP:
cpu_idx = 0; /* ARP packet handled on separate CPU */
break;
default:
cpu_idx = 0;
}
/* Choose CPU based on L4 protocol */
switch (ip_proto) {
case IPPROTO_ICMP:
case IPPROTO_ICMPV6:
cpu_idx = 2;
break;
case IPPROTO_TCP:
cpu_idx = 0;
break;
case IPPROTO_UDP:
cpu_idx = 1;
break;
default:
cpu_idx = 0;
}
cpu_lookup = bpf_map_lookup_elem(&cpus_available, &cpu_idx);
if (!cpu_lookup)
return XDP_ABORTED;
cpu_dest = *cpu_lookup;
if (cpu_dest >= nr_cpus) {
NO_TEAR_INC(rec->issue);
return XDP_ABORTED;
}
return bpf_redirect_map(&cpu_map, cpu_dest, 0);
}
other NIC
重定向到其他网卡和 XDP_TX 类似, 不同点在于前者是从另一个网卡发送, 而后者是从同一个网卡发送.
重定向的网卡不一定要是物理网卡, 也可是虚拟网卡, 只要其驱动需要实现ndo_xdp_xmit函数即可, 比如 tun 网卡.
重定向网卡的例子可以参考 https://github.com/xdp-project/xdp-tools/blob/master/xdp-bench/xdp_redirect_devmap.bpf.c
static __always_inline int xdp_redirect_devmap(struct xdp_md *ctx, void *redirect_map)
{
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
__u32 key = bpf_get_smp_processor_id();
struct ethhdr *eth = data;
struct datarec *rec;
__u64 nh_off;
nh_off = sizeof(*eth);
if (data + nh_off > data_end)
return XDP_DROP;
rec = bpf_map_lookup_elem(&rx_cnt, &key);
if (!rec)
return XDP_PASS;
NO_TEAR_INC(rec->processed);
swap_src_dst_mac(data);
return bpf_redirect_map(redirect_map, 0, 0);
}
SEC("xdp")
int redir_devmap_general(struct xdp_md *ctx)
{
return xdp_redirect_devmap(ctx, &tx_port_general);
}
an AFXDP socket
AFXDP socket 是一种与 AF-INET socket 平级的 socket 类型, 应用程序可以创建这种类型的 socket 实现绕过内核协议栈的报文收发.
在接收方向上, 就是 XDP eBPF 程序将报文重定向到一个 AFXDP socket 完成的, 这需要借助 BPF_MAP_TYPE_XSKMAP 实现.
例子可参考: https://github.com/xdp-project/xdp-tutorial/blob/master/advanced03-AF_XDP/af_xdp_kern.c
SEC("xdp")
int xdp_sock_prog(struct xdp_md *ctx)
{
int index = ctx->rx_queue_index;
u32 *pkt_count;
pkt_count = bpf_map_lookup_elem(&xdp_stats_map, &index);
if (pkt_count) {
/* We pass every other packet */
if ((*pkt_count)++ & 1)
return XDP_PASS;
}
/* A set entry here means that the correspnding queue_id
* has an active AF_XDP socket bound to it. */
if (bpf_map_lookup_elem(&xsks_map, &index))
return bpf_redirect_map(&xsks_map, index, 0);
return XDP_PASS;
}
一些旧内核 bpf_redirect_map 的坑
在一些旧版本内核(如debian10 默认的 4.19内核中), eBPF 程序中 bpf_redirect_map 函数功能是不够好的.
以下摘自 4.19内核的 include/uapi/linux/bpf.h 中,
* int bpf_redirect_map(struct bpf_map *map, u32 key, u64 flags)
* Description
* Redirect the packet to the endpoint referenced by *map* at
* index *key*. Depending on its type, this *map* can contain
* references to net devices (for forwarding packets through other
* ports), or to CPUs (for redirecting XDP frames to another CPU;
* but this is only implemented for native XDP (with driver
* support) as of this writing).
*
* All values for *flags* are reserved for future usage, and must
* be left at zero.
*
* When used to redirect packets to net devices, this helper
* provides a high performance increase over **bpf_redirect**\ ().
* This is due to various implementation details of the underlying
* mechanisms, one of which is the fact that **bpf_redirect_map**\
* () tries to send packet as a "bulk" to the device.
* Return
* **XDP_REDIRECT** on success, or **XDP_ABORTED** on error.
也就是, 只要 eBPF 程序调用了这个函数, 报文一定是会被丢弃(XDP_ABORTED)或者重定向(XDP_REDIRECT), 而再不能 XDP_PASS.
这就使得如果我希望编写一个满足下面这个条件的 eBPF 程序就会比较麻烦: 收到的UDP报文目标端口是一定范围(可动态设置)就 XDP_REDIRECT, 否则 XDP_PASS.
原因是, 由于要支持动态设置, 因此不能 eBPF 程序内 hardcode, 而需要用到 map (用户态程序可写).
此时, 我并不能用以下语句实现
return bpf_redirect_map(&udp_redir_map, dest_port, 0);
因为, 一旦调用它, 返回的不是 XDP_REDIRECT 就是 XDP_ABORTED, 而不能是 XDP_PASS.
为此, 我只能定义一个辅助 map, 先检查 dest_port 是否在这个辅助 map 里, 如果在, 再调用 bpf_redirectp.
int* ifindex = bpf_map_lookup_elem(&udp_redir_map, &dest);
if (ifindex && *ifindex > 0)
action = bpf_redirect(*ifindex, 0);
而再较新的内核里, bpf_redirect_map 有了改变, 它支持设置缺省值(在 map 查询 key 失败后的缺省动作)
* long bpf_redirect_map(struct bpf_map *map, u32 key, u64 flags)
* Description
* Redirect the packet to the endpoint referenced by *map* at
* index *key*. Depending on its type, this *map* can contain
* references to net devices (for forwarding packets through other
* ports), or to CPUs (for redirecting XDP frames to another CPU;
* but this is only implemented for native XDP (with driver
* support) as of this writing).
*
* The lower two bits of *flags* are used as the return code if
* the map lookup fails. This is so that the return value can be
* one of the XDP program return codes up to **XDP_TX**, as chosen
* by the caller. The higher bits of *flags* can be set to
* BPF_F_BROADCAST or BPF_F_EXCLUDE_INGRESS as defined below.
*
* With BPF_F_BROADCAST the packet will be broadcasted to all the
* interfaces in the map, with BPF_F_EXCLUDE_INGRESS the ingress
* interface will be excluded when do broadcasting.
*
* See also **bpf_redirect**\ (), which only supports redirecting
* to an ifindex, but doesn't require a map to do so.
* Return
* **XDP_REDIRECT** on success, or the value of the two lower bits
* of the *flags* argument on error.
此时, 我们就可直接使用
return bpf_redirect_map(&udp_redir_map, dest_port, XDP_PASS);