VPP: fifo-segment

本系列文章仅为学习使用 VPP 过程中的一些自用笔记
VPP 中的 fifo 是什么
在 VPP/VCL HostStack 模型中,fifo 是作为连接(session)的发送缓冲区和接收缓冲区存在的.
发送方向,应用通过 VCL 将数据塞入txfifo, VPP 从 txfifo 中读取;
接收方向,VPP 将收到报文塞入连接的 rxfifo, 应用通过 rxfifo 读取数据.
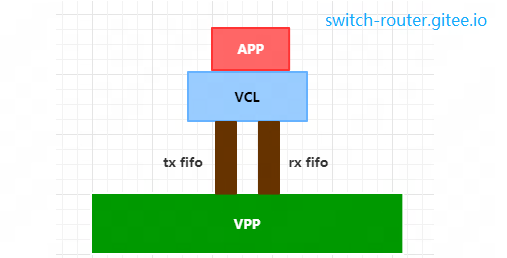
fifo 本质上是一段VPP进程和APP进程都可以访问的共享内存,并且,它总是以 fifo pair 的形式成对出现的,一条连接 (VPP 上看到的一个 session)总是对应确定的一各 fifo pair。
VPP 中的 fifo_segment 是什么
fifo_segment 则是 fifo 的管理者,它管理一定数量的 fifo。当需要分配 fifo 时,VPP 先去从 fifo_segment 中看是否存在可用的 fifo 资源,如果没有了,再去创建新的fifo_segment了。
除了fifo_segment之外,还有一个概念是 segment_manager, 这是一个比 fifo_segment 更大的概念。
一个segment_manager包含并管理多个 fifo_segment,每个fifo_segment属于唯一的segment_manager
而segment_manager又是属于谁呢?它属于一个app_worker,app_worker是 VPP 视角下看到的 APP 的工作线程。一个app_worker拥有一个或多个segment_manager
所以以上几个概念之间的关系是
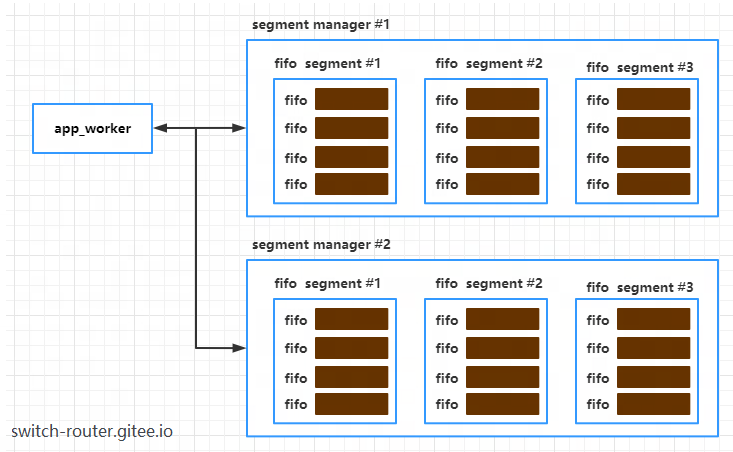
segment manager 的创建
VPP 在创建每一个app_worker在创建时就会创建一个segment_manager.
int
application_alloc_worker_and_init (application_t * app, app_worker_t ** wrk)
{
...
sm = segment_manager_alloc ();
sm->app_wrk_index = app_wrk->wrk_index;
segment_manager_init (sm, app->sm_properties.segment_size,
app->sm_properties.prealloc_fifos)
app_wrk->first_segment_manager = segment_manager_index (sm);
...
}
先看下 segment_manager 的数据结构, segments 即是它管理的 fifo_segment 的池子.
typedef struct _segment_manager
{
/** Pool of segments allocated by this manager */
fifo_segment_t *segments;
......
/** Owner app worker index */
u32 app_wrk_index;
......
} segment_manager_t;
不考虑配置了prealloc_fifos选项的场景,此时 VPP 不会预先将 fifo 全部创建出来,而只会向这个segment_manager添加一个 segment.
int
segment_manager_init (segment_manager_t * sm, uword first_seg_size,
u32 prealloc_fifo_pairs)
{
segment_manager_props_t *props;
int seg_index;
.....
props = segment_manager_properties_get (sm); // propertie is associate with application
first_seg_size = clib_max (first_seg_size, sm_main.default_segment_size);
// 向 segment manager 添加创建一个 first_seg_size 大小的 segment
seg_index = segment_manager_add_segment (sm, first_seg_size);
...
}
向 segment_manager 添加 fifo_segment
segment 的大小可以在 vcl.conf 中指定,若不指定的话默认是 1M, 这个大小尽量设置成 PageSize 的整数倍(且至少为2).
即是不这样设置, VPP 也会将其 align 到 Page 的整数倍。对应地,使用 HugePage 时,这个值尽量设置成 HugePageSize 大小的整数倍。
向segment_manager添加新的 segment 是在segment_manager_add_segment完成的。在这之前,我们先看看fifo_segment_t的数据结构
typedef struct
{
ssvm_private_t ssvm; /**< ssvm segment data */
fifo_segment_header_t *h; /**< fifo segment data */
u8 n_slices; /**< number of fifo segment slices */
} fifo_segment_t;
其中 ssvm 记录了这个segment相关的共享内存相关的数据,包括共享内存的起止范围,创建者的PID (也就是VPP的PID) 等信息。
而h则指向了一个fifo_segment_header_t数据结构,它记录的是旗下 fifo 的的分配信息,比如空闲 fifo 列表等…
n_slices 的值为 VPP 的线程数目,这个参数的意义在于: VPP 在多线程条件下,可以各自分配 fifo 而互不干扰。
共享内存的方式
当前 VPP 支持两种方式的内存共享:shm 和 memfd;我们当前使用后者,VPP 作为共享内存的 master 创建一个匿名文件,得到其 fd,
并使用 mmap 将其文件内存映射到指定的虚拟内存空间上。之后再将这个 fd 发送给 VCL, VCL侧 attach 到相同的虚拟地址空间。
int
segment_manager_add_segment (segment_manager_t * sm, uword segment_size)
{
uword baseva = (uword) ~ 0ULL, alloc_size, page_size;
fifo_segment_t *fs;
// 从 segment manager池冲 取出一个 fifo segment
pool_get_zero (sm->segments, fs);
...
// 省略计算分配共享内存大小的计算
alloc_size = (uword) segment_size;
// 分配一个将要作为共享内存基址的虚拟地址
baseva = clib_valloc_alloc (&smm->va_allocator, alloc_size, 0);
// 初始化 fifo segment
fs->ssvm.ssvm_size = segment_size;
fs->ssvm.name = seg_name;
fs->ssvm.requested_va = baseva;
......
// 使用指定类型的 master 初始化函数进行共享内存的设置, 对 memfd 类型来说就是ssvm_master_init_memfd
ssvm_master_init (&fs->ssvm, props->segment_type)
// 此时已经完成了地址映射,现在进行 fifo element 的初始化
fs->n_slices = props->n_slices;
fifo_segment_init (fs);
......
}
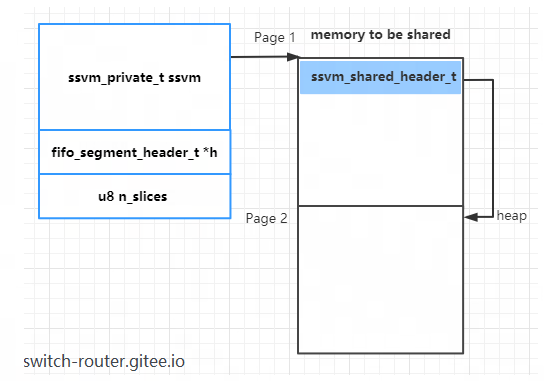
先来看ssvm_master_init_memfd,其中完建 memfd 和 mmap,在映射空间的开头放置了一个ssvm_shared_header_t结构,
heap 则指向映射空间所在 page 的后一个 Page (当使用HugePage时,则为第二个 HugePage),注意这里传入的参数就是fifo_segment的 ssvm
int
ssvm_master_init_memfd (ssvm_private_t * memfd)
{
uword page_size;
ssvm_shared_header_t *sh;
clib_mem_vm_alloc_t alloc = { 0 };
alloc.name = (char *) memfd->name; // segment name
alloc.size = memfd->ssvm_size; // segment size
alloc.flags = CLIB_MEM_VM_F_SHARED | CLIB_MEM_VM_F_HUGETLB; // shared segment and use hugetlb
alloc.requested_va = memfd->requested_va; // allocated virtual address range
// 内部完成 创建memfd 和 mmap
clib_mem_vm_ext_alloc (&alloc)
// 将以下信息记录到 fifo segment
memfd->fd = alloc.fd;
memfd->sh = (ssvm_shared_header_t *) alloc.addr; // 指向映射地址空间的起始处
memfd->my_pid = getpid ();
memfd->i_am_master = 1;
// sh 在映射地址空间的起始处
page_size = 1ull << alloc.log2_page_size;
sh = memfd->sh;
sh->master_pid = memfd->my_pid;
sh->ssvm_size = memfd->ssvm_size;
sh->ssvm_va = pointer_to_uword (sh);
sh->type = SSVM_SEGMENT_MEMFD;
......
// 将 sh->heap 设置为映射地址空间的第二个页地址
sh->heap = create_mspace_with_base (((u8 *) sh) + page_size,
memfd->ssvm_size - page_size,
1 /* locked */ );
......
}
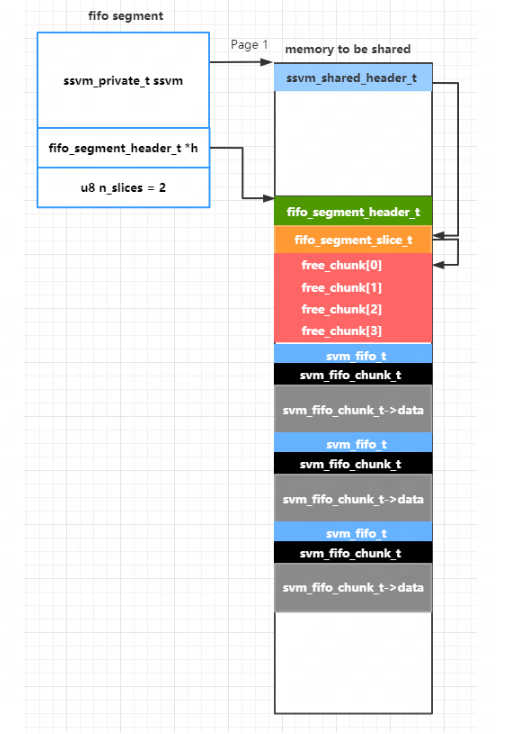
所以,在完成了 master init 后,fifo_segment 和映射的内存空间的内存布局入下图所示 (假设映射了 2 个 Page):
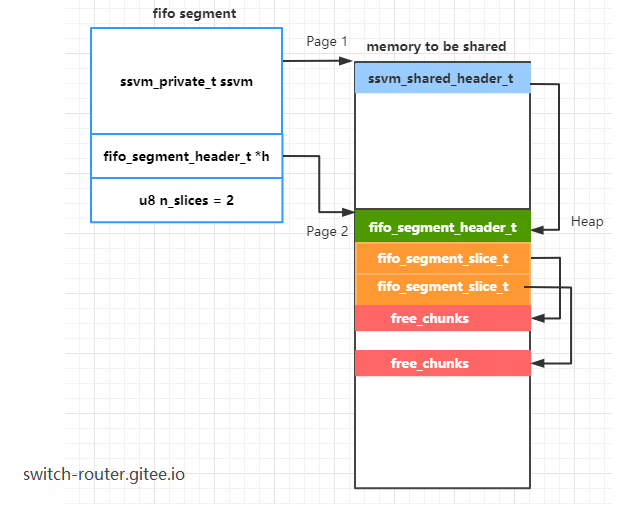
紧接着,继续 fifo segment 的初始化,其中主要是在映射空间的第二个 Page 放置 1 个fifo_segment_header_t结构和 slices 个fifo_segment_slice_t结构
int
fifo_segment_init (fifo_segment_t * fs)
{
fifo_segment_header_t *fsh;
fifo_segment_slice_t *fss;
ssvm_shared_header_t *sh;
u32 max_chunk_sz, max_chunks;
uword max_fifo;
void *oldheap;
int i;
// 这里 fs->ssvm.sh 指向映射空间的起始地址
sh = fs->ssvm.sh;
// 切换heap到 映射空间的第二个Page
oldheap = ssvm_push_heap (sh);
// 在第二个Page的开头放置一个 fifo_segment_header_t 结构
fsh = clib_mem_alloc_aligned (sizeof (*fsh), sizeof (uword));
clib_memset (fsh, 0, sizeof (*fsh));
fs->h = sh->opaque[0] = fsh;
fs->n_slices = clib_max (fs->n_slices, 1);
fsh->ssvm_sh = fs->ssvm.sh;
fsh->n_slices = fs->n_slices;
// 计算单个 fifo 容量的最大值
max_fifo = clib_min ((fsh_free_space (fsh) - 4096) / 2, FIFO_SEGMENT_MAX_FIFO_SIZE);
fsh->max_log2_chunk_size = max_log2 (max_fifo);
// 再接着放置 fsh->slices 个 fifo_segment_slice_t 结构
fsh->slices = clib_mem_alloc (sizeof (*fss) * fs->n_slices);
clib_memset (fsh->slices, 0, sizeof (*fss) * fs->n_slices);
max_chunk_sz = fsh->max_log2_chunk_size - FIFO_SEGMENT_MIN_LOG2_FIFO_SIZE; // 20-12 = 8
for (i = 0; i < fs->n_slices; i++)
{
fss = fsh_slice_get (fsh, i);
vec_validate_init_empty (fss->free_chunks, max_chunk_sz, 0);
}
// 恢复 heap
ssvm_pop_heap (oldheap);
......
return (0);
}
假设 slices 为 2,则 fifo segment 初始化完成后 fifo segment 和映射空间的内存布局如下图所示
fifo 与 chunk
前面的代码中设计到了 chunk 的概念。 chunk 是 fifo 的内存单元,应用实际的数据也都是存储在 chunk 内部的内存中,
一个 fifo 可以关联一个或多个 chunk。下面是 fifo 和 chunk 的数据结构。
typedef struct _svm_fifo
{
...
svm_fifo_chunk_t *start_chunk;/**< first chunk in fifo chunk list */
svm_fifo_chunk_t *end_chunk; /**< end chunk in fifo chunk list */
...
}svm_fifo_t;
typedef struct svm_fifo_chunk_
{
u32 start_byte; /**< chunk start byte */
u32 length; /**< length of chunk in bytes */
struct svm_fifo_chunk_ *next; /**< pointer to next chunk in linked-lists */
u8 data[0]; /**< start of chunk data */
} svm_fifo_chunk_t;
它们之间的联系如下图所示:
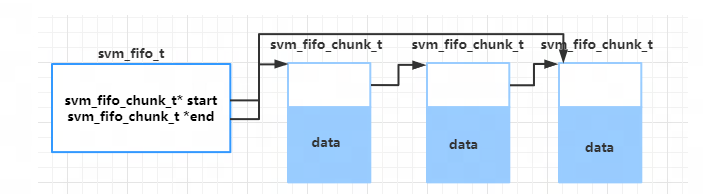
svm_fifo_t 保存 fifo 的控制信息, svm_fifo_chunk_t 组成的链表中的每一个节点都有一片 data 数据区域保存实际的数据。
fifo 和 chunk 资源都是记录在 slice 资源上, 本质上也就是记录在 fifo segment 上。
typedef struct fifo_segment_slice_
{
svm_fifo_t *fifos; /**< Linked list of active RX fifos */
svm_fifo_t *free_fifos; /**< Freelists by fifo size */
svm_fifo_chunk_t **free_chunks; /**< Freelists by chunk size */
uword n_fl_chunk_bytes; /**< Chunk bytes on freelist */
} fifo_segment_slice_t;
fifo slice 的布局如下图所示
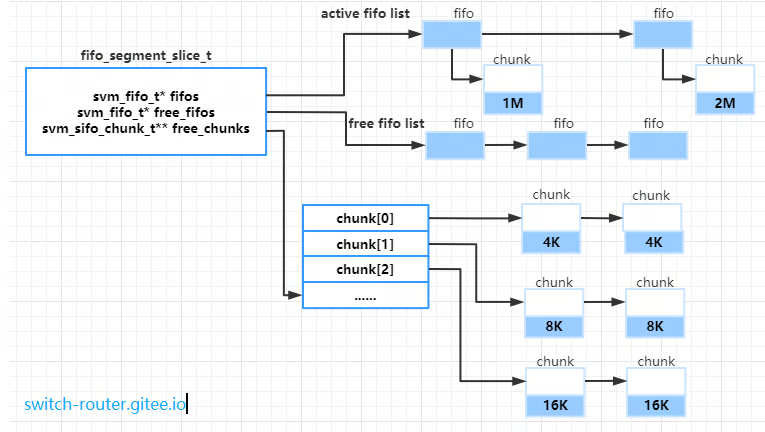
- active fifos 链表上的 fifo 表示正在使用的,它们都关联了 chunk,也就是都有实际的存储空间,
- free fifos 链表上的 fifo 串联起来的是空闲的 fifo,这些 fifo 还没有关联 chunk。
- free chunks 指向一个 chunk 链表的数组,数组的大小在创建 fifo segment 时就计算好了,并且每一层的chunk的容量都是上一层的2倍。 这样在创建 fifo 时,VPP 就可以根据创建 fifo 的大小,选择合适的 chunk 作为存储空间
创建 fifo
svm_fifo_t *
fifo_segment_alloc_fifo_w_slice (fifo_segment_t * fs, u32 slice_index,
u32 data_bytes, fifo_segment_ftype_t ftype)
{
fifo_segment_header_t *fsh = fs->h;
fifo_segment_slice_t *fss;
svm_fifo_t *f = 0;
// 根据当前线程slice_index,找到对应的 fifo_segment_slice_t 结构
fss = fsh_slice_get (fsh, slice_index);
// 在 fifo_segment_slice_t 结构上尝试创建容量为 data_bytes 的fifo
f = fs_try_alloc_fifo (fsh, fss, data_bytes);
......
}
在 fifo_segment_slice_t 创建 fifo 的片段如下
static svm_fifo_t *
fs_try_alloc_fifo (fifo_segment_header_t * fsh, fifo_segment_slice_t * fss,
u32 data_bytes)
{
u32 fifo_sz, fl_index;
svm_fifo_t *f = 0;
uword n_free_bytes;
// 根据 fifo 大小找到合适 chunk 大小
fl_index = fs_freelist_for_size (data_bytes);
// 每一个 fifo 除了实际的内存空间外 还有 svm_fifo_t 和 svm_fifo_chunk_t 的控制信息
fifo_sz = sizeof (svm_fifo_t) + sizeof (svm_fifo_chunk_t);
fifo_sz += 1 << max_log2 (data_bytes);
if (fss->free_fifos && fss->free_chunks[fl_index])
{
// 如果 free_fifos 链表和 free_chunks[fl_index] 链表上有现成的,则直接使用现成的
f = fs_try_alloc_fifo_freelist (fss, fl_index, data_bytes);
if (f)
goto done;
}
....
// 否则 则需要重新从 segment 上批量规划处新的内存区域,创建新的 free fifo 和 free chunks
n_free_bytes = fsh_n_free_bytes (fsh);
if (fifo_sz * FIFO_SEGMENT_ALLOC_BATCH_SIZE < n_free_bytes)
{
// 批量创建 svm_fifo_t 和 svm_fifo_chunk_t
if (fs_try_alloc_fifo_batch (fsh, fss, fl_index,
FIFO_SEGMENT_ALLOC_BATCH_SIZE))
goto done;
f = fs_try_alloc_fifo_freelist (fss, fl_index, data_bytes);
goto done;
}
批量创建 svm_fifo_t 和 svm_fifo_chunk_t 的本质就是在 fifo segment 的 heap 上划出新的区域.
static int
fs_try_alloc_fifo_batch (fifo_segment_header_t * fsh,
fifo_segment_slice_t * fss,
u32 fl_index, u32 batch_size)
{
u32 hdrs, rounded_data_size;
svm_fifo_chunk_t *c;
svm_fifo_t *f;
void *oldheap;
uword size;
u8 *fmem;
int i;
// 计算需要申请的内存总大小
rounded_data_size = fs_freelist_index_to_size (fl_index);
hdrs = sizeof (*f) + sizeof (*c);
size = (uword)(hdrs + rounded_data_size) * batch_size;
// 使用 共享内存空间上的 heap 空间
oldheap = ssvm_push_heap (fsh->ssvm_sh);
fmem = clib_mem_alloc_aligned_at_offset (size, CLIB_CACHE_LINE_BYTES,
0 /* align_offset */ ,
0 /* os_out_of_memory */ );
ssvm_pop_heap (oldheap);
......
/* Carve fifo + chunk space */
for (i = 0; i < batch_size; i++)
{
f = (svm_fifo_t *) fmem;
memset (f, 0, sizeof (*f));
f->next = fss->free_fifos;
fss->free_fifos = f;
c = (svm_fifo_chunk_t *) (fmem + sizeof (*f));
c->start_byte = 0;
c->length = rounded_data_size;
c->next = fss->free_chunks[fl_index];
fss->free_chunks[fl_index] = c;
fmem += hdrs + rounded_data_size;
}
fss->n_fl_chunk_bytes += batch_size * rounded_data_size;
fsh_free_bytes_sub (fsh, size);
return 0;
}
其内部布局上,如下图所示。注意,尽管批量创建时,每个 svm_fifo_t 都是和 svm_fifo_chunk_t 是连在一起的,
但实际上两者并不一定关联在一起,它们在逻辑上还是处于各自的空闲链表上。
如何提高 fifo segment 利用率
从上面的内存布局中我们可以看出,并不是所有共享内存空间都可以用来容纳实际的报文数据。下面一些区域是不能使用的
- fifo segment 的第一个 Page (HugePage)。所有的 chunk 都是从第二个 Page (HugePage开始)
- 第二个Page的开始处。这里还要存放 fifo segment header、fifo segment slice 等结构
- svm_fifo_t 和 svm_fifo_chunk_t 结构占用。
因此为了能让 segment 的利用率更高,我们应该让 segment 的 size 尽可能大,这样可以减少第一个 Page (HugePage 的浪费)
举例
在使用 2M 大小的 HugePge , 配置 segment size 大小为 4M 时. 在分配了 16 个 15K 大小的fifo后,剩余空闲可用的 1.41M,
换算一下如果不分配,则初始空闲剩余应该稍稍大于1.64M,此时利用率为 1.64M/4M = 41%
932064-7 memfd 4 0 16 204400000
Free chunks by size:
16 kB: 8
16 kB: 8
seg free bytes: 1.41m (1480400) estimated: 1.41m (1480784)
chunk free bytes: 256k (262144) estimated: 256k (262144)
fifo hdr free bytes: 4k (4096) reserved 3.97k (4064)
如果将 segment size 大小调整为 8M,同样在分配了 16 个 15K 大小的fifo,剩余空闲空间为 5.4M,
换算一下初始剩余空间应该稍微大于 5.63M,此时利用率为 5.63M/8M=70%
932064-14 memfd 8 0 16 205400000
Free chunks by size:
16 kB: 8
16 kB: 8
seg free bytes: 5.40m (5666480) estimated: 5.40m (5666864)
chunk free bytes: 256k (262144) estimated: 256k (262144)
fifo hdr free bytes: 4k (4096) reserved 11.97k (12256)
(完)