从 UDP bind 的一次优化谈起

事情的起因是在查找关于IP_BIND_ADDRESS_NO_PORT选项的来历, 往前翻 patch 记录时找到了udp: bind() optimisation这个commit.
本文正是关于这个patch的一些理解和思考.
这个patch解决什么问题呢? 这里引用 commit msg 原文:
UDP bind() can be O(N^2) in some pathological cases. Thanks to secondary hash tables, we can make it O(N)
说明该 patch 是为了优化 UDP 调用 bind 时的效率.
在这个 patch 前几天的另一个patch之前, udp 只有一个 hashtable 组织所有的 udp socket.
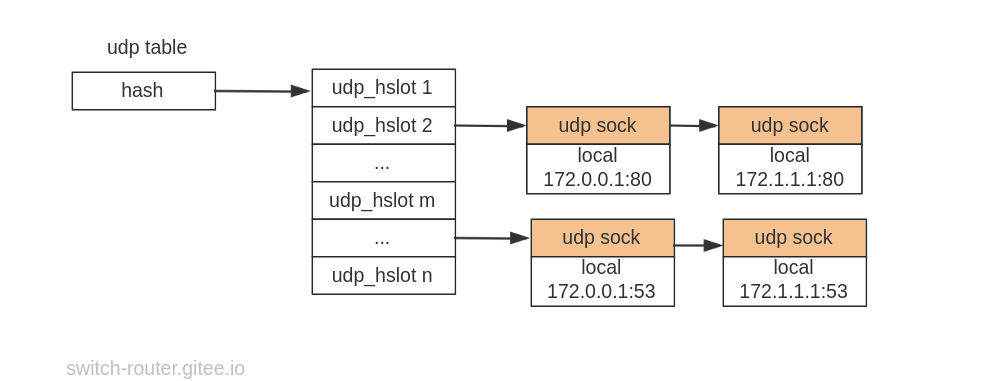
内核中的所有 udp socket 根据本端端口被分到不同的 hslot, 而完全不考虑本端地址
如此一来, 不同本地地址 + 相同本地端口(或hash值相同的不同本地端口) 的 socket 就会落到放到同一个 hslot 中,
也就是说, 这个 hashtable 只是降低了一层查找维度, 在本地地址数量很多的场景中, 查找复杂度为 O(N^2).
而这个patch使用了 secondary hash 表,
它将本地地址也纳入计算范围. 这样一来, 不同本地地址 + 相同本地端口(或hash值相同的不同本地端口) 的 socket 就会被打散到不同的 hlost 中
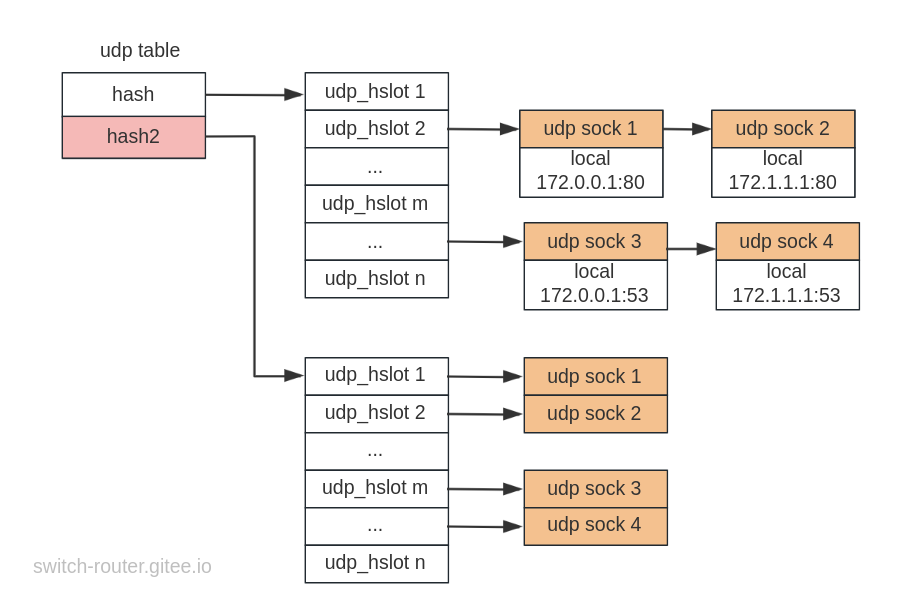
实际的实现中, 使用哪个 table 遵循以下两条规则:
- 先从一元组hash表查找, 只有在 hslot 长度超过 10 时, 才在新的二元组hash表中查找冲突.
- 如果从二元组hash表找到的 hslot 更长, 则还是回退到使用一元组hash表.
总之原则就是, 从更容易的地方下手.
更上一层楼
上面的这个优化通过 一元组–>二元组 来减少 bind() 在一些场景下的查找时间. 那么可以让 udp 干脆保存四元组吗 ?
其实是可以的, 并且这在一些场景下是有意义的.
我们知道, udp 在接收消息查找 socket 时, 总是会去找一个最合适的 socket, 四元组匹配的就比二元组匹配的更合适.
对于一个 udp 服务端来说, 在只有二元组 hash 表时, 所有不同来源的 udp socket 都在一个 hslot, 要找到最合适的就需要遍历整个链表
但如果有以一个四元组hash, 就可以先从四元组hash开始查找.