理解内核 TCP 的重传次数

sysctl_tcp_retries1和sysctl_tcp_retries2是内核提供的与 TCP 重传次数的相关的两个控制开关.
其中sysctl_tcp_retries2 (后文简称retries2)与我们普通认知中的最大重传次数的关系更为密切.
文档的原文是这么写的:
This value influences the timeout of an alive TCP connection, when RTO retransmissions remain unacknowledged.Given a value of N, a hypothetical TCP connection following exponential backoff with an initial RTO of TCP_RTO_MIN would retransmit N times before killing the connection at the (N+1)th RTO.
那我们可以说,retries2的值就是最大重传次数吗?
很遗憾, 并不是.
TCP 完全可能在重传次数没有达到retries2时, 就放弃这条连接.
要搞清楚这个问题, 我们要知道两点.
- ESTABLISHED 状态的 TCP 连接初始初始超时时间 RTO 来自 srtt, 且需要在
TCP_RTO_MIN(200ms)~TCP_RTO_MAX(120s)之间 - 每次重传的间隔遵循指数退避原则. 比如第一次1s, 第二次2s, 第三次4s, 以此类推..最大不超过
TCP_RTO_MAX(120s)
接下来我们看看 sysctl_tcp_retries2 是如何生效的
// 重传超时时调用
tcp_write_timeout(struct sock *sk) {
...
retry_until = READ_ONCE(net->ipv4.sysctl_tcp_retries2);
...
expired = retransmits_timed_out(sk, retry_until, READ_ONCE(icsk->icsk_user_timeout));
if (expired) {
// 放弃这条连接
tcp_write_err(sk);
}
}
重点就是在retransmits_timed_out, 如果它返回 true, 则表示这条连接没救了.
static bool retransmits_timed_out(struct sock *sk,
unsigned int boundary,
unsigned int timeout)
{
struct tcp_sock *tp = tcp_sk(sk);
unsigned int start_ts, delta;
...
// 重传计时器的起点时间戳
start_ts = tp->retrans_stamp;
if (likely(timeout == 0)) {
unsigned int rto_base = TCP_RTO_MIN;
...
// 用 TCP_RTO_MIN 和 retries2 算出极限首尾重传时间间隔
timeout = tcp_model_timeout(sk, boundary, rto_base);
}
...
// 如果当前时间戳 - 重传计时器起点 > 首尾极限重传间隔, 返回 true
return (s32)(tcp_time_stamp_ts(tp) - start_ts - timeout) >= 0;
}
判断是否放弃连接的依据就是当前时刻与首次重传时刻的间隔是否超过了首尾极限重传间隔
而 极限重传间隔 只又由TCP_RTO_MIN和retries2决定. (这里不考虑用户通过 setsockopt 设置 icsk_user_timeout的场景)
TCP_RTO_MIN是固定的 200ms 常量, retries2是可以通过 sysctl 进行设置
最后看看首尾极限重传间隔的计算:
static unsigned int tcp_model_timeout(struct sock *sk,
unsigned int boundary,
unsigned int rto_base)
{
unsigned int linear_backoff_thresh, timeout;
linear_backoff_thresh = ilog2(TCP_RTO_MAX / rto_base);
if (boundary <= linear_backoff_thresh)
timeout = ((2 << boundary) - 1) * rto_base;
else
timeout = ((2 << linear_backoff_thresh) - 1) * rto_base +
(boundary - linear_backoff_thresh) * TCP_RTO_MAX;
return jiffies_to_msecs(timeout);
}
可以看出, timeout 由线性区(也可以理解为指数退避区)加上非线性区.
在rto_base为200ms的通常情况中, 线性退避阈值linear_backoff_thresh为 ilog2(120/0.2) = 9
以retries2的默认取值 15 计算,
timeout = (2 << 9)-1)*200ms + (15-9)*120s = 924.6s
也就是说, 默认情况下, 如果此时距离首次重传已经过去超过 924.6s, 则会放弃重传
我们还可以推算出不同retries2对应的timeout:
retries2=14 timeout = (2 << 9)-1)*200ms + (14-9)*120s = 804.6s
retries2=13 timeout = (2 << 9)-1)*200ms + (13-9)*120s = 684.6s
...
retries2=9 timeout = (2 << 9)-1)*200ms = 204.6s
retries2=8 timeout = (2 << 8)-1)*200ms = 102.2s
retries2=7 timeout = (2 << 7)-1)*200ms = 51.0s
retries2=6 timeout = (2 << 6)-1)*200ms = 25.4s
...
直到这里, retries2的值看上去就是最大重传次数.
但这个结论的前提就是首次重传的时间RTO是200ms! 也就是最开始重传时 srtt 不能大于 200ms.
如果其大于 200ms, 就会导致后面重传的间隔按比例扩大, 这样就会更快进入retries2对应的首尾极限重传间隔.
对比 retries2为6时, RTO为200ms和1200ms的场景:
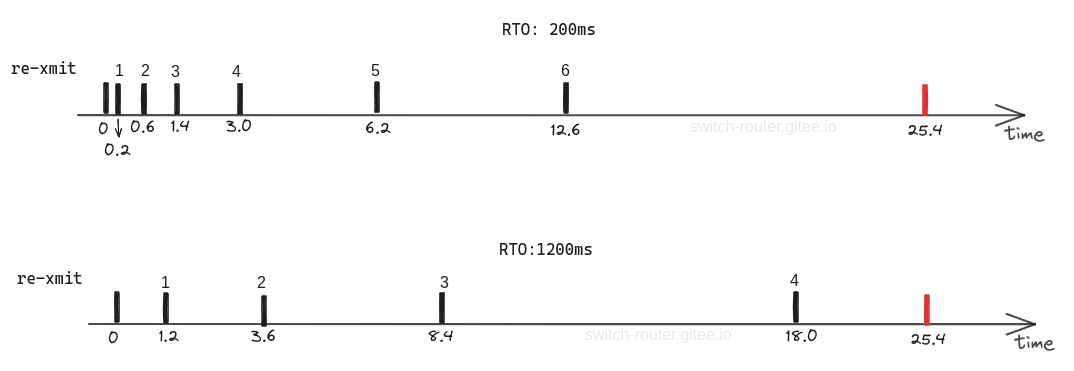
RTO为默认的 200ms 时, 最多能重传6次, 而当RTO 为1200ms时, 便只能重传4次 (因为第5次超时就已经超过了 25.4s 的极限收尾间隔)
总结
sysctl_tcp_retries2所指示的重传次数实际上隐含了初始重传时间为200ms, 如果条件不满足时, 重传次数会小于该数值.