理解 sack reordering distance

在不使能 SACK 时, 发送端在收到默认 3 个 DupAcks , 就会立即触发快速重传和快速恢复.
这一点使用下面的 packetdrill 很轻松验证:
// author. @switch-router.gitee.io
+0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
+0 < S 0:0(0) win 32792 <mss 1000,nop,wscale 7>
+0 > S. 0:0(0) ack 1 win 64240 <mss 1460,nop,wscale 7>
+.1 < . 1:1(0) ack 1 win 257
+0 accept(3, ..., ...) = 4
+0 write(4, ..., 1000) = 1000
+0 > P. 1:1001(1000) ack 1
+0 write(4, ..., 1000) = 1000
+0 > P. 1001:2001(1000) ack 1
+0 write(4, ..., 1000) = 1000
+0 > P. 2001:3001(1000) ack 1
+0 write(4, ..., 1000) = 1000
+0 > P. 3001:4001(1000) ack 1
+0 write(4, ..., 1000) = 1000
+0 > P. 4001:5001(1000) ack 1
// INJECT 1 normal ack
+0 < . 1:1(0) ack 1001 win 257
// INJECT 3 dup ack
+0 < . 1:1(0) ack 1001 win 257
+0 < . 1:1(0) ack 1001 win 257
+0 < . 1:1(0) ack 1001 win 257
// We've received 3 duplicate ACKs, so we do a fast retransmit.
+0 > P. 1001:2001(1000) ack 1
+0 < . 1:1(0) ack 5001 win 257
当使能了 SACK 之后, 情况稍微变得复杂一些, 按照rfc6675的描述,快速重传依然会在下面这个式子成立时发生.
DupAcks >= DupThresh
需要注意, 这里的DupAcks和不使用SACK时的定义并不一样, 这一点在rfc6675有相关描述,
不过这个不是本文重点, 本文重点是DupThresh.
与不使用 SACK 时固定值相比, 此时的DupThresh是一个动态变化的值, 在内核中由 tcp 连接的下面这个字段维护.
struct tcp_sock {
...
u32 reordering; /* Packet reordering metric. */
...
}
其初始值为 sysctl_tcp_reordering(默认值为3), 之后可以在运行时通过函数 tcp_check_sack_reordering() 动态调整,
但最大不超过sysctl_tcp_max_reordering (默认值为300).
我所理解的它的含义是: 该 TCP 连接在接纳 SACK 时能忍受的重排序难度
我们知道, SACK 是为了在报文传输乱序或者丢包时, 接收端也能向发送端通告部分报文已经送达. 避免发送端重复传输.
reordering的计算方法是: 在确认网络会出现乱序时, 序号最高的 SACK block 的尾与 SND_UNA 之间的距离, 单位是该连接的 MSS.
为了体会其意义, 我们先做两个实验
实验1: 发送方向接收方发送6个报文, 接收方正常应答第1个ack, 随后应答3个携带SACK block 的ack.
0 `sysctl -q net.ipv4.tcp_sack=1`
0 `sysctl -q net.ipv4.tcp_recovery=0`
+0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
// 3-way handshake
+0 < S 0:0(0) win 32792 <mss 1000,sackOK,nop,nop,nop,wscale 7>
+0 > S. 0:0(0) ack 1 win 64240 <mss 1460,nop,nop,sackOK,nop,wscale 7>
//0.100 > S. 0:0(0) ack 1 <mss 1460,nop,nop,sackOK,nop,wscale 6>
+.1 < . 1:1(0) ack 1 win 257
+0 accept(3, ..., ...) = 4
// Write extra 7 data segments.
+0 write(4, ..., 1000) = 1000
+0 > P. 1:1001(1000) ack 1
+0 write(4, ..., 1000) = 1000
+0 > P. 1001:2001(1000) ack 1
+0 write(4, ..., 1000) = 1000
+0 > P. 2001:3001(1000) ack 1
+0 write(4, ..., 1000) = 1000
+0 > P. 3001:4001(1000) ack 1
+0 write(4, ..., 1000) = 1000
+0 > P. 4001:5001(1000) ack 1
+0 write(4, ..., 1000) = 1000
+0 > P. 5001:6001(1000) ack 1
// INJECT 1 normal ack
+0 < . 1:1(0) ack 1001 win 257
// INJECT 2 dup ack with sack
+0 < . 1:1(0) ack 1001 win 257 <sack 2001:4001,nop,nop>
+0 < . 1:1(0) ack 1001 win 257 <sack 4001:5001,nop,nop>
// INJECT 1 dup ack with sack.
+0 < . 1:1(0) ack 1001 win 257 <sack 5001:6001,nop,nop>
+0 > P. 1001:2001(1000) ack 1 win 502
+0 < . 1:1(0) ack 6001 win 257
抓包结果如下, 可以看到, 方框中的报文表示发送方进行了快速重传.
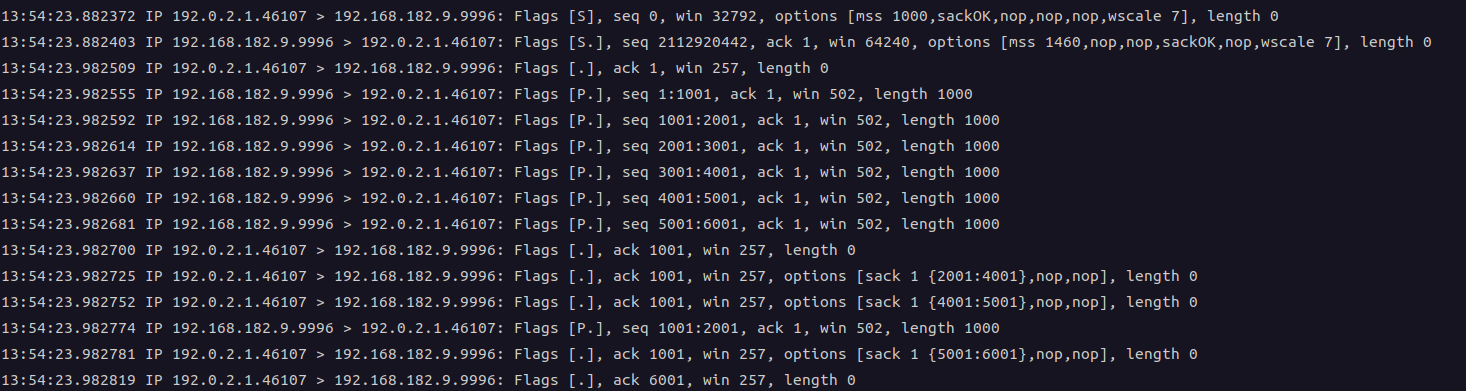
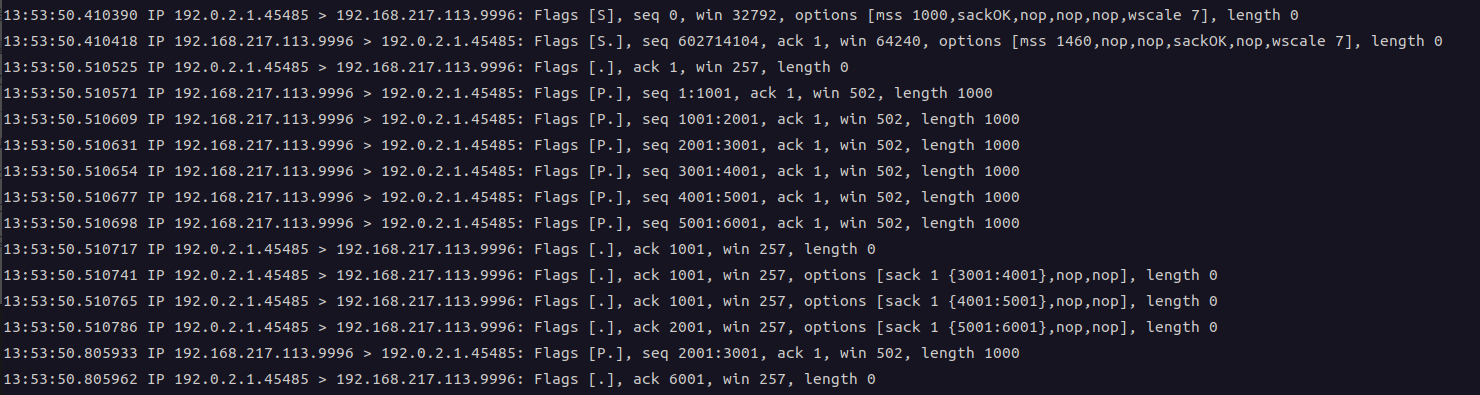
实验2: 发送方向接收方发送6个报文, 接收方正常应答第1个ack, 随后应答3个携带SACK block 的ack. 与实验1不同的地方在于第三个 ack 应答了 2001
0 `sysctl -q net.ipv4.tcp_sack=1`
0 `sysctl -q net.ipv4.tcp_recovery=0`
+0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
// 3-way handshake
+0 < S 0:0(0) win 32792 <mss 1000,sackOK,nop,nop,nop,wscale 7>
+0 > S. 0:0(0) ack 1 win 64240 <mss 1460,nop,nop,sackOK,nop,wscale 7>
//0.100 > S. 0:0(0) ack 1 <mss 1460,nop,nop,sackOK,nop,wscale 6>
+.1 < . 1:1(0) ack 1 win 257
+0 accept(3, ..., ...) = 4
// Write 6 data segments.
+0 write(4, ..., 1000) = 1000
+0 > P. 1:1001(1000) ack 1
+0 write(4, ..., 1000) = 1000
+0 > P. 1001:2001(1000) ack 1
+0 write(4, ..., 1000) = 1000
+0 > P. 2001:3001(1000) ack 1
+0 write(4, ..., 1000) = 1000
+0 > P. 3001:4001(1000) ack 1
+0 write(4, ..., 1000) = 1000
+0 > P. 4001:5001(1000) ack 1
+0 write(4, ..., 1000) = 1000
+0 > P. 5001:6001(1000) ack 1
// INJECT 1 normal ack
+0 < . 1:1(0) ack 1001 win 257
// INJECT 2 dup ack with sack
+0 < . 1:1(0) ack 1001 win 257 <sack 3001:4001,nop,nop>
+0 < . 1:1(0) ack 1001 win 257 <sack 4001:5001,nop,nop>
// INJECT 1 dup ack with sack . 重点关注这个 ack 报文
+0 < . 1:1(0) ack 2001 win 257 <sack 5001:6001,nop,nop>
+0 > P. 2001:3001(1000) ack 1 win 502
+0 < . 1:1(0) ack 6001 win 257
而结果呢, 并没有发生快速重传.
分析原因
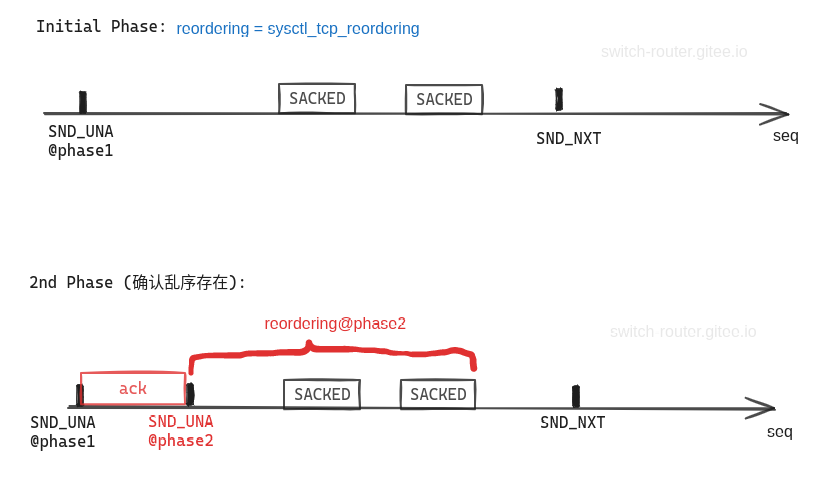
比较两个实验, 区别就是实验2的第3个带 SACK 的 ack 将 SND_UNA 向前推进了.
发送端在收到这个 ack 前, 尚不能确定没有按序到达的 [1001,2001]和 [2001,3001] 是丢了还是乱序.
而在收到之后可以就可以确定了: 网络的确存在乱序
此时就可以调整 reordering 的值
内核实现上, 参考函数tcp_check_sack_reordering的实现.
static void tcp_check_sack_reordering(struct sock *sk, const u32 low_seq,
const int ts)
{
struct tcp_sock *tp = tcp_sk(sk);
const u32 mss = tp->mss_cache;
u32 fack, metric;
fack = tcp_highest_sack_seq(tp);
...
metric = fack - low_seq;
if ((metric > tp->reordering * mss) && mss) {
tp->reordering = min_t(u32, (metric + mss - 1) / mss,
sock_net(sk)->ipv4.sysctl_tcp_max_reordering);
}
.....
}
注意tp->reordering的值是单调递增的. 调整之后, 再想触发快速重传, 就要 DupAck 超过这个新的tp->reordering了.
我理解这样做的理由是发送方快速重传的本质是担心报文丢失,但是如果事实证明网络的确会存在这种程度的乱序, 那就不妨多等一会儿.
(完)