SMC-R 加速 TCP
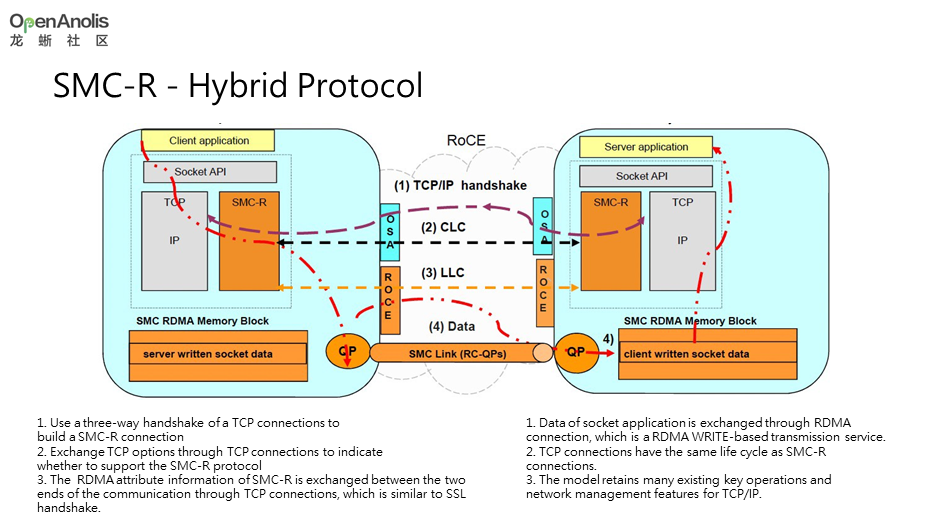
Shared Memory Communication over RDMA (SMC-R) 是一项基于 RDMA 技术的内核态网络协议,目标是在应用无感知的状态下,提升 TCP 应用网络性能(实现更高带宽和更低时延)。SMC-R 协议(RFC7609)由 IBM 首先提出,现已合入 Linux 社区, 且还在不断的演进…
高吞吐和低时延的网络是数据面不懈追求. 而近年来越发火热的 RDMA 成为了许多人眼中实现这一目标的利剑.
加速的本质
关于 RDMA 的基本原理, 互联网上已经有不少资料了. 比如 RDMA杂谈 本文不再详述.
RDMA 的加速原理并不是让报文在线缆或者交换机之间传输地更快 (毕竟都是电信号, 大家没什么不同).
本质上看, RDMA 是将原本需要消耗 CPU 处理报文的工作 Offload 到网卡,CPU 不再需要花时间在 TCP 协议栈上, 而可以用省下来的 CPU 处理更多业务逻辑, 从而减少通信时延.
但要想让 RDMA 取得相较 TCP 的显著优势, 个人认为还需要满足两个条件:
- 处理业务的 CPU 资源很宝贵
反过来说, 如果业务本身并不忙, CPU 资源本身并不稀缺, 那么 RDMA 省下的 CPU 意义并不大。
- 通信双方之间的 RTT 并不大
如果网络传输在路径上占比很大,则 RDMA 方案中将协议栈卸载到网卡的所带来的收益将变得很小。因此, RDMA 多用于数据中心内部。
另外, RDMA 其实比 TCP 对基础网络的稳定性要求更高,对丢包更难以忍受…
软件上阻碍
现实的网络应用,绝大部分直接或者间接使用 posix API 与内核交互,我们已经习惯了socket()、bind()、listen().
就算你是 java 程序员, 也会间接地使用上面这些函数对应的系统调用…
但是 RDMA 使用的 Verbs API 不一样,它的接口更多, 语义也和 posix API 大不相同。
比如 ibv_create_qp ibv_modify_qp ibv_post_send
如果决心要使用 RDMA,新的应用还可以迁就,但现存的应用怎么办?
粘合剂 SMC-R
软件工程中,遇到上下层不兼容的情况下,惯用的手段是加入一个中间层作为粘合剂。SMC-R 就是这样的角色。
对上层,SMC-R 劫持应用的 socket() 调用,移花接木地将应用本来想创建的 TCP socket 篡改为新发明的 SMC-R socket。
应用以为 socket() 返回的 fd 是一个 tcp 套接字,殊不知已经被替换成了 SMC-R。
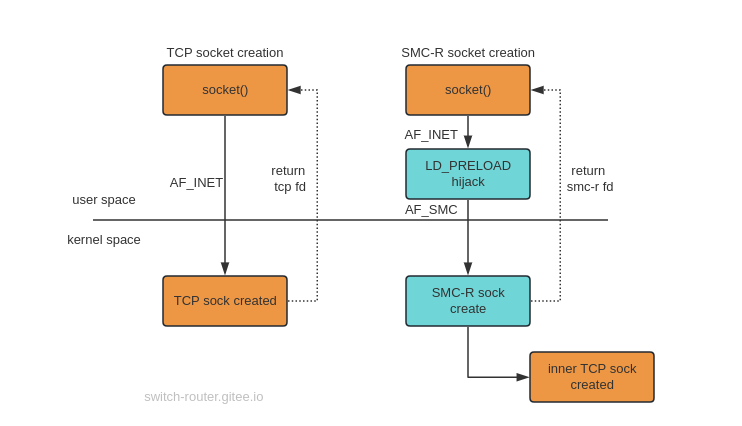
今后应用在这个 fd 上的一切操作,比如读写数据,内核都不再走 tcp 那一套了,而是由 SMC-R 内核模块调用 Verbs API 操作。
应用在这个过程中不会使用 Verbs API ! 它感知不到 SMC-R 的存在!
性能实测
我们使用 memtier_benchark + redis 来对比下 SMC-R 和 TCP 的性能差异,下面是运行结果

结果表明, 使用 SMC-R 大幅度提升了增加了QPS,降低了latency.