一个 qdisc 引起报文阻塞问题
问题现象
使用 (fortio)[https://github.com/fortio/fortio] 进行时延测试,有概率出现 target999 的时延超出正常范围。
测试设置并发数 c=8, qps=16, 即一共使用8条连接, 每条连接的qps=2 (每500ms发送一次http请求)
ip netns exec busybox-n213 taskset -c "12-23" fortio load -c 8 -qps 16 ......
......
> 0.00055 <= 0.0006 , 0.000575 , 99.38, 1
> 0.0006 <= 0.0007 , 0.00065 , 99.58, 1
> 0.0009 <= 0.001 , 0.00095 , 99.79, 1
> 0.5 <= 0.508805 , 0.504403 , 100.00, 1 <===== 有的请求往返时间在 0.5ms 以上
# target 50% 0.000314823
# target 75% 0.000341372
# target 90% 0.000393421
# target 99% 0.00051
# target 99.9% 0.504579 <===== 不正常地大
并且,若修改参数 qps=32 (每条连接的 qps 为 4, 每 250ms发送一个 http 请求),则 target999 异常时将变为稍大于 250ms 的一个值。
总结现象: 异常时延与 fortio 发包间隔有关系.
问题分析
以下是在并发数为8,总qps为32时的抓包结果 (fortio客户端每250ms发送一批(8个)请求)
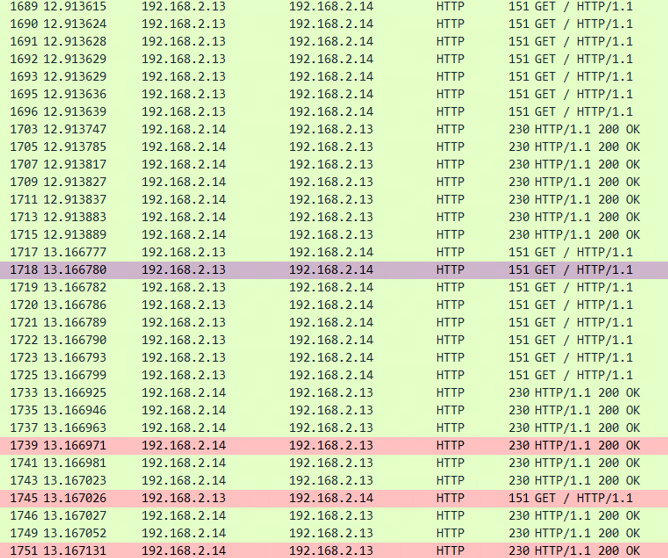
然而, 我们会发现,在12.9136s处,本该发出8个请求,但实际只发出了7个,余下的1个请求(编号1718)出现在了下一批(时间13.166s)处,即这个请求晚了250ms!
内核问题定位
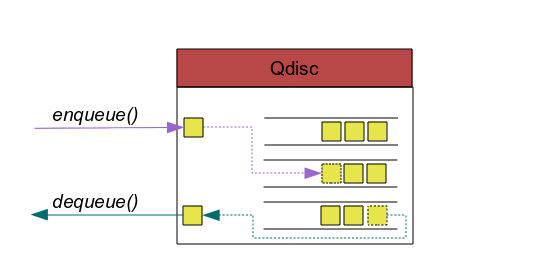
使用 kprobe 在内核的以下关键路径上设置监控, 一个正常的请求报文会依次通过下面三个函数
- net_dev_queue: 协议栈将报文送入 qdisc 队列
- qdisc_dequeue: qdisc 从队列中取出报文
- net_dev_xmit: 报文送到 driver 发送
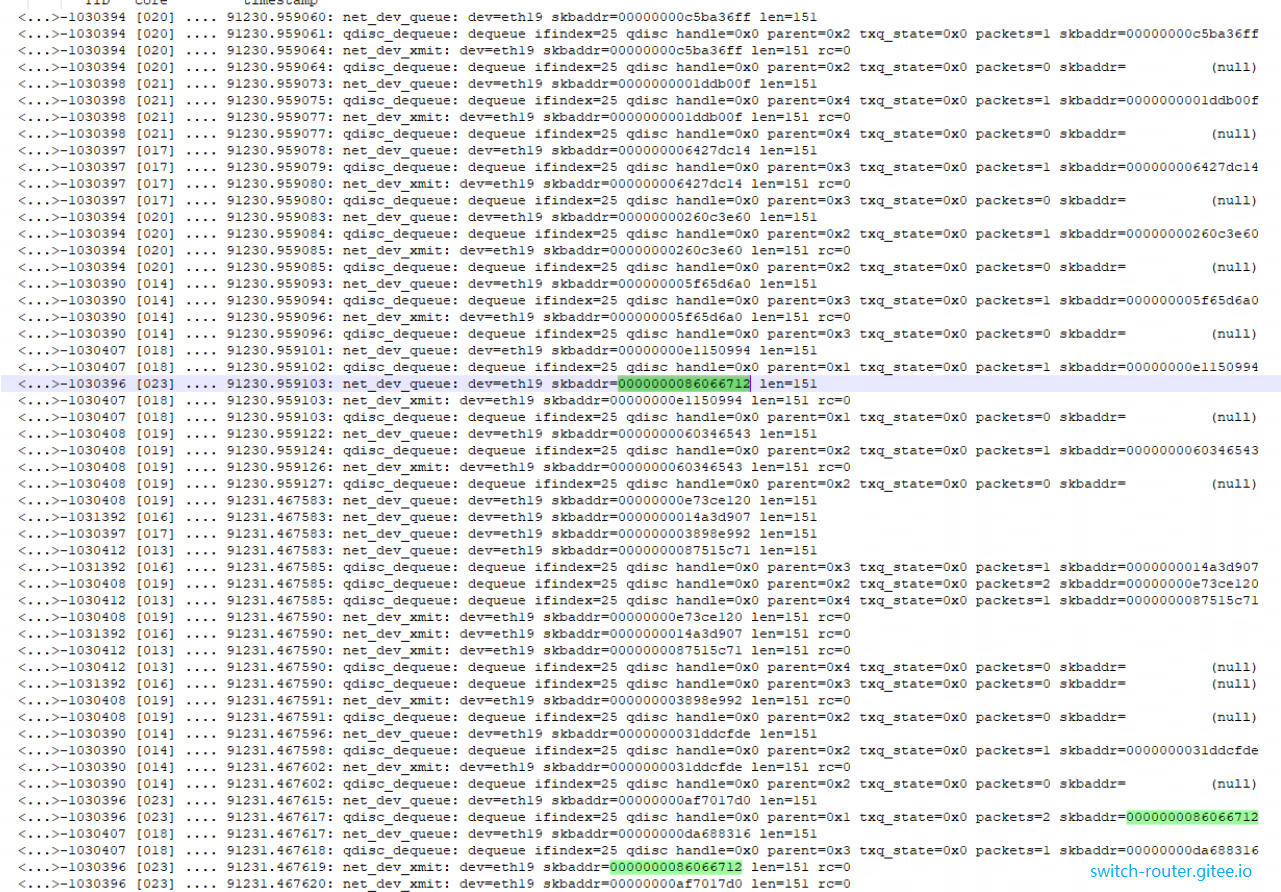
上图前4条记录(时间戳1030394)显示了最正常的的情况:

- 报文 skb 00000000c5ba36ff 进入qdisc队列
- qdisc 从队列中取出 skb 00000000c5ba36ff
- net_dev_xmit 发送 skb 00000000c5ba36ff
- qdisc 中队列空
qdisc_dequeue 会执行多次直到该qdisc上没有报文, 可以将三个函数之间的关系裂解为:
net_dev_queue(q,skb)
while (skb = qdisc_dequeue(q)) {
net_dev_xmit(skb)
}
回到上面那张完整的结果, 可以看到绿色高亮的报文 0000000086066712 在时刻 91230.959103 由 core 23 入队列, 但是却是在时刻 91231.467617 才由 core 23 将其从 qdisc 中取出, 整整晚了 500ms
那么问题就变成了为什么这个报文没有在被 core 23 在第一时间取出完成
当前环境中,网卡采用的 pfifo_fast 型 qdisc 有 4 个 qdisc 队列 ,每个 core 都可以将报文放入每个 qdisc 队列, 其编号就为上面图中的 parent=0x1 到 0x4 ,任一时刻,一个 qdisc 队列只能被一个 core 所运行(run)
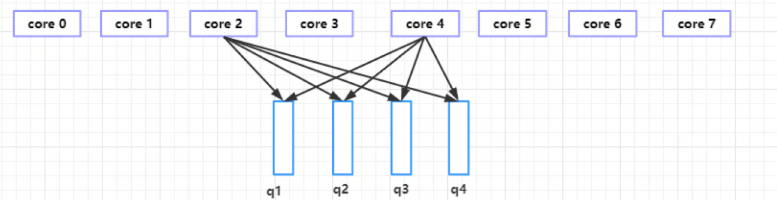
从时刻91231.467617 可以看到, 问题报文的是从 parent=0x1 的队列中被 qdisc_dequeue 取出, 说明它当初是被 enqueue 到 parent=0x1 号队列.
q->enqueue(skb) 在以下函数被调用:
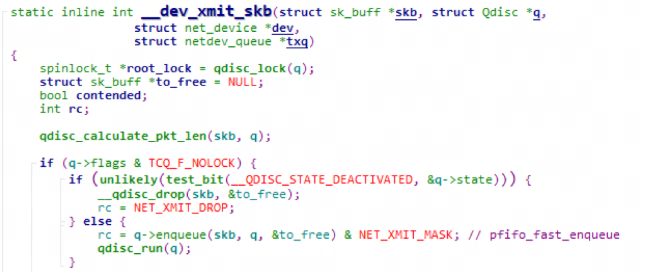
可以看到, 报文一旦 qneueue, qdisc_run() 就被被调用. 然而后者内部会尝试获取 qdisc->seqlock. 如果获取失败(该锁正在被其他core所持有), 则放弃立即 __qdisc_run()
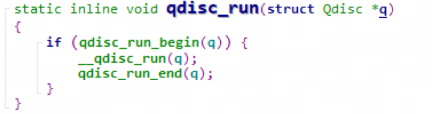

总结一下就是: 报文入队列一定成功, 但出队列却可能因为并发而失败
那失败之后怎么办呢? 只要有其他报文再次加入这个队列,就可以获得再次 trylock 的机会.
观察记录中问题报文出问题的时间段附近, 可以看到:

按时间线分析就是:
(1) 时刻 .959101: core 18 入队列报文 e1150994 (2) 时刻 .959102: core 18 取出 1 个报文 e1150994, core 18 qdsic_run_start 获取锁 (3) 时刻 .959103: core 23 准备入队列报文 86066712 (打印 net_dev_queue) core 18 发出 1 个报文 e1150994, 再检查 qdisc,此刻没有报文 core 23 入队列 86066712 (完成) core 23 尝试 qdsic_run_begin 失败 (此时锁还被 core 18 占据) 退出 core 18 qdsic_run_end 释放锁
这样 报文 86066712 就没有被取出。只有再下次 qdisc 1 被使用的时候(时刻 91231.467617 ) 被取出 ==> 可以看到这个时候 disc中有 packet = 2 个报文!这是不正常的!

至此, 我们解开了问题出现的原因:多核场景,Qdisc 的无锁优化造成的报文不能及时从 Qdisc 队列中取出
修改措施
问题原因找到了, 怎么修改呢? 这里我想有两个办法
方案一:去掉 pfifo_fast 的 NOLOCK 特性
这个特性在 https://lwn.net/Articles/698135/ 有描述, 无锁化之前, core 在 入qdisc 、 run qdisc 时 都是 core 间互斥的,而 nolock 特性 使得将这个保护粒度缩小到了 run qdisc 的范围, 这样一来,如果一个 core 正在 run qdisc (不断取出报文给driver), 另一个core 可以将报文 入 qdisc,这个报文会由前一个 core 处理,也就是说,报文入 qdisc 时的core 不一定是 报文在 run qdisc时处理的 core
方案二:修改运行 Qdisc 的逻辑
原生的Qdisc实现,内核运行qdisc时,并不区分是否真的可以入队列。因此,可以增加一个判断,当没有能入对列时,触发一个sorfirq,这样让报文有补救发出的机会。
(完)