解析 pwru:基于 eBPF 的网络包跟踪神器
![]()
网络问题的排查往往是最令工程师头疼的挑战之一。当一个数据包在复杂的网络栈中”消失”时,传统的调试工具往往力不从心—— tcpdump 只能看到网卡层面的流量,而应用层的日志又缺乏底层网络的细节。
数据包究竟在内核的哪个环节被丢弃?是防火墙规则?路由问题?还是 socket buffer 满了?
如果你曾经为了追踪一个莫名其妙的网络连接超时而在对着 netstat、ss、iptables 输出发呆,那么今天介绍的这个工具会让你眼前一亮。pwru(packet, where are you?)(https://github.com/cilium/pwru)是 Cilium 团队开发的一个基于 eBPF 的网络包跟踪工具,它能够以极低的性能开销,实时跟踪数据包在 Linux 内核网络栈中的完整流向。
下面这个来自官方的使用例子生动展示了 pwru 的用法:

整体架构设计思路
pwru 的架构设计体现了现代 eBPF 应用的典型模式:用户空间控制器 + 内核空间数据平面。这种设计哲学源于一个核心理念:将复杂的逻辑处理放在用户空间,将高频的数据处理放在内核空间,从而实现性能与灵活性的最佳平衡。
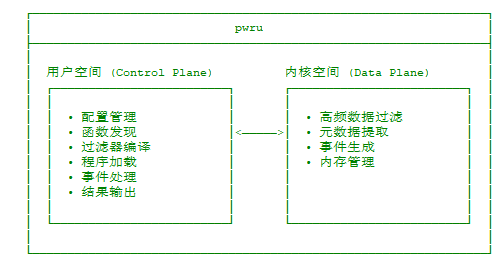
运行时的协作流程如下图所示:

源码级别剖析
由上可知, pwru 仓库功能可分为用户态和内核态两部分, 下面分别阐述
内核态程序
内核态程序的核心在bpf/kprobe_pwru.c, 以下是各部分的简要说明
bpf/kprobe_pwru.c
├─ 数据结构定义
│ ├─ struct event_t // 事件结构
│ ├─ struct skb_meta // SKB 元数据
│ ├─ struct tuple // 网络元组
│ └─ struct config // 全局配置
│
├─ eBPF Maps
│ ├─ events // 事件队列 (用户空间通信)
│ ├─ skb_addresses // SKB 跟踪表
│ ├─ print_skb_map // SKB 打印缓冲区
│ ├─ print_stack_map // 调用栈表
│ └─ veth_skbs // veth 设备特殊处理
│
├─ 过滤器函数
│ ├─ filter_pcap() // pcap 过滤 (动态注入)
│ ├─ filter_meta() // 元数据过滤
│ ├─ filter_skb_expr() // 自定义表达式过滤
│ └─ filter() // 总过滤器
│
├─ 数据提取函数
│ ├─ set_meta() // 提取 SKB 元数据
│ ├─ set_tuple() // 提取网络元组
│ ├─ set_tunnel() // 提取隧道信息
│ └─ set_output() // 汇总输出数据
│
├─ kprobe 程序组
│ ├─ kprobe_skb_1() // 第1个参数是 sk_buff*
│ ├─ kprobe_skb_2() // 第2个参数是 sk_buff*
│ ├─ ... // 最多支持到第5个参数
│ └─ kprobe_multi_*() // kprobe-multi 版本
│
├─ 特殊场景处理
│ ├─ fentry_tc() // TC BPF 程序跟踪
│ ├─ fentry_xdp() // XDP 程序跟踪
│ ├─ fexit_skb_clone() // SKB 克隆跟踪
│ └─ kprobe_skb_lifetime_termination() // SKB 生命周期
│
└─ 工具函数
├─ get_netns() // 获取网络命名空间
├─ get_stackid() // 获取调用栈 ID
├─ handle_everything() // 事件处理总入口
└─ get_addr() // 获取函数地址
eBPF maps
events和skb_addresses是用的最多的 map。
events - 事件通信队列 (主要通信通道)
#define MAX_QUEUE_ENTRIES 10000
struct {
__uint(type, BPF_MAP_TYPE_QUEUE);
__type(value, struct event_t);
__uint(max_entries, MAX_QUEUE_ENTRIES);
} events SEC(".maps");
events队列是用户空间和内核空间之间的主要通信通道,它的底层是有个 FIFO 队列, 所有跟踪事件都通过这个队列传递。
使用场景:
// 内核空间推送事件
bpf_map_push_elem(&events, &event, BPF_EXIST);
// 用户空间读取事件 (Go)
events.LookupAndDelete(nil, &event)
skb_addresses - SKB 地址跟踪表
#define MAX_TRACK_SIZE 1024
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__type(key, __u64); // SKB 指针地址
__type(value, bool); // 跟踪标志
__uint(max_entries, MAX_TRACK_SIZE);
} skb_addresses SEC(".maps");
skb_addresses队列跟踪需要持续监控的 SKB 对象,实现 “数据包生命周期跟踪”。
当数据包首次匹配过滤条件时,将其 SKB 地址加入此表,后续该 SKB 经过其他函数时,即使不匹配过滤条件也会被跟踪, SKB 被释放时从表中删除。
使用示例:
// 检查 SKB 是否已被跟踪
if (bpf_map_lookup_elem(&skb_addresses, &skb_addr)) {
tracked_by = TRACKED_BY_SKB;
goto process_event;
}
// 将新匹配的 SKB 加入跟踪
if (filter(skb)) {
bpf_map_update_elem(&skb_addresses, &skb_addr, &TRUE, BPF_ANY);
}
// SKB 销毁时清理
bpf_map_delete_elem(&skb_addresses, &skb_addr);
kprobe 程序组
pwru 的 kprobe 程序组设计基于一个核心思想:在内核的不同网络层级和关键点上插桩,实现对 sk_buff 生命周期的全链路追踪。
从实现上看, 它分为了以下 5 个层次

PWRU_ADD_KPROBE
PWRU_ADD_KPROBE 是一个非常精巧的宏,它是pwru项目中用于自动生成多个kprobe处理函数的核心机制.
#define PWRU_ADD_KPROBE(X) \
SEC("kprobe/skb-" #X) \
int kprobe_skb_##X(struct pt_regs *ctx) { \
struct sk_buff *skb = (struct sk_buff *) PT_REGS_PARM##X(ctx); \
return kprobe_skb(skb, ctx, NULL, false); \
} \
\
SEC("kprobe.multi/skb-" #X) \
int kprobe_multi_skb_##X(struct pt_regs *ctx) { \
struct sk_buff *skb = (struct sk_buff *) PT_REGS_PARM##X(ctx); \
return kprobe_skb(skb, ctx, NULL, true); \
}
使用时:
PWRU_ADD_KPROBE(1)
PWRU_ADD_KPROBE(2)
PWRU_ADD_KPROBE(3)
PWRU_ADD_KPROBE(4)
PWRU_ADD_KPROBE(5)
每个PWRU_ADD_KPROBE(X)都生成两个函数:
传统kprobe版本:
SEC("kprobe/skb-1")
int kprobe_skb_1(struct pt_regs *ctx) {
// 从第1个参数获取SKB
struct sk_buff *skb = (struct sk_buff *) PT_REGS_PARM1(ctx);
return kprobe_skb(skb, ctx, NULL, false); // false = 传统kprobe
}
kprobe-multi版本:
SEC("kprobe.multi/skb-1")
int kprobe_multi_skb_1(struct pt_regs *ctx) {
// 从第1个参数获取SKB
struct sk_buff *skb = (struct sk_buff *) PT_REGS_PARM1(ctx);
return kprobe_skb(skb, ctx, NULL, true); // true = kprobe-multi
}
我们知道, 内核中有一些函数, 将 skb 作为参数时, 传递的位置不尽相同. 比如:
// 第1个参数是SKB的函数
int netif_rx(struct sk_buff *skb);
int netif_receive_skb(struct sk_buff *skb);
// 第2个参数是SKB的函数
int dev_queue_xmit_nit(struct sk_buff *skb, struct net_device *dev);
int packet_rcv(struct sk_buff *skb, struct net_device *dev, ...);
// 第3个参数是SKB的函数
int br_handle_frame(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt);
通过这个宏,pwru能够自动适配不同参数位置的SKB函数.
实际运行时, 控制平面Go代码, 会将函数按参数位置分组:
// internal/pwru/utils.go
func GetFuncsByPos(funcs Funcs) map[int][]string {
ret := make(map[int][]string, len(funcs))
for fname, pos := range funcs {
ret[pos] = append(ret[pos], fname)
}
return ret
}
然后在添加 kprobe 探测点时, 根据函数的SKB参数位置选择对应的eBPF程序.
// internal/pwru/kprobe.go
funcsByPos := GetFuncsByPos(funcs)
for pos, fns := range funcsByPos {
progName := fmt.Sprintf("kprobe_skb_%d", pos) // 对应宏生成的函数名
if prog := coll.Programs[progName]; prog != nil {
pwruKprobes = append(pwruKprobes, Kprobe{HookFuncs: fns, Prog: prog})
}
}
kprobe_skb_by_stackid
kprobe_skb_by_stackid主要用于附加到用户指定的参数非skb的内核函数. 常规的 SKB kprobe 只能处理 sk_buff *skb 这样参数的函数.
但内核中存在一些函数, 他们没有 sk_buff *skb 参数.
static rx_handler_result_t br_handle_frame(struct sk_buff **pskb) // 是二级指针
此时 pwru 就可以借助栈来在追踪:
调用栈示例:
┌──────────────────────────────┐
│ netif_receive_skb() │ ← SKB在第1个参数,建立stackid映射
│ └─ br_handle_frame() │ ← 没有SKB参数,但通过stackid找到SKB
│ └─ br_forward() │ ← 没有SKB参数,但通过stackid找到SKB
│ └─ dev_queue_xmit()│ ← SKB重新出现在参数中
└──────────────────────────────┘
第一步:建立映射
// 在 netif_receive_skb(skb) 中
u64 stackid = get_stackid(ctx, true); // 获取调用栈唯一标识
bpf_map_update_elem(&stackid_skb, &stackid, &skb, BPF_ANY); // stackid → skb
bpf_map_update_elem(&skb_stackid, &skb, &stackid, BPF_ANY); // skb → stackid
第二步:通过栈查找
// 在 br_handle_frame() 中
SEC("kprobe/skb_by_stackid")
int kprobe_skb_by_stackid(struct pt_regs *ctx) {
u64 stackid = get_stackid(ctx, true); // 获取当前调用栈标识
// 查找这个调用栈关联的SKB
struct sk_buff **skb = bpf_map_lookup_elem(&stackid_skb, &stackid);
if (skb && *skb) {
// 找到了!继续用标准流程处理这个SKB
return kprobe_skb(*skb, ctx, &stackid, false);
}
return BPF_OK;
}
kprobe_skb_lifetime_termination
kprobe_skb_lifetime_termination 唯一且固定地附加到内核函数 kfree_skbmem,它的主要作用是可以防止地址重用导致的追踪错误
// internal/pwru/skb_tracker.go:29
kp, err := link.Kprobe("kfree_skbmem", coll.Programs["kprobe_skb_lifetime_termination"], nil)
kfree_skbmem 是 Linux 内核网络子系统中 SKB内存管理的最底层函数,它在所有 SKB 释放路径的最终汇聚点。
正常消费路径:
consume_skb() → __kfree_skb() → kfree_skbmem()
异常丢弃路径:
kfree_skb() → __kfree_skb() → kfree_skbmem()
设备层释放:
dev_kfree_skb() → __dev_kfree_skb() → __kfree_skb() → kfree_skbmem()
引用计数归零:
skb_unref() → __kfree_skb() → kfree_skbmem()
网络命名空间清理:
netns_cleanup() → ... → kfree_skbmem()
下面是内存地址重用导致的误追踪触发的场景
// 时刻 T1: SKB A 被分配
struct sk_buff *skb_a = alloc_skb(1500, GFP_KERNEL); // 地址:0xffff8800deadbeef
// pwru 开始追踪 SKB A
bpf_map_update_elem(&skb_addresses, &skb_a, &TRUE, BPF_ANY);
// 时刻 T2: SKB A 处理完成,但 pwru 不知道
consume_skb(skb_a); // 释放到 slab 缓存
// 时刻 T3: 新的 SKB B 复用了相同地址
struct sk_buff *skb_b = alloc_skb(1500, GFP_KERNEL); // 地址:0xffff8800deadbeef (重用!)
// 时刻 T4: pwru 错误地认为 SKB B 就是之前追踪的 SKB A
if (bpf_map_lookup_elem(&skb_addresses, &skb_b)) {
// 错误!这不是我们要追踪的包
handle_everything(skb_b, ...);
}
解决方案就是及时清理,避免地址重用误匹配
SEC("kprobe/skb_lifetime_termination")
int kprobe_skb_lifetime_termination(struct pt_regs *ctx) {
struct sk_buff *skb = (typeof(skb)) PT_REGS_PARM1(ctx);
u64 skb_addr = (u64) skb;
bpf_map_delete_elem(&skb_addresses, &skb_addr);
}
fexit_skb_clone 和 fexit_skb_copy
这两个程序的附着点是 skb_clone 和 skb_copy. 虽然他们的参数包含 struct sk_buff *skb, 但它们不能使用 PWRU_ADD_KPROBE
原因是 kprobe 无法获取函数返回值, 而对这两个函数, 我们需要同时访问原始的sk_buff *old和sk_buff *new (返回值), 以建立跟踪关系
struct sk_buff *skb_clone(struct sk_buff *skb, gfp_t gfp_mask);
struct sk_buff *skb_copy(const struct sk_buff *skb, gfp_t gfp_mask);
假设使用 PWRU_ADD_KPROBE(1) 追踪 skb_clone
SEC("kprobe/skb-1")
int kprobe_skb_1(struct pt_regs *ctx) {
struct sk_buff *old_skb = (struct sk_buff *) PT_REGS_PARM1(ctx);
// 问题:此时函数还未执行,new_skb 还不存在!
// struct sk_buff *new_skb = ???; // 无法获取
// 只能追踪原始 SKB,无法处理克隆关系
return kprobe_skb(old_skb, ctx, NULL, false);
}
如果尝试使用 kretprobe
SEC("kretprobe/skb_clone")
int kretprobe_skb_clone(struct pt_regs *ctx) {
struct sk_buff *new_skb = (struct sk_buff *) PT_REGS_RC(ctx); // 返回值
// 问题:此时已经无法获取原始的 old_skb 了!
// struct sk_buff *old_skb = ???; // 参数已经不可访问
return BPF_OK;
}
而 fexit 探测点的优势就是同时访问参数和返回值
SEC("fexit/skb_clone")
int BPF_PROG(fexit_skb_clone, struct sk_buff *old, gfp_t mask, struct sk_buff *new) {
// ↑ 输入参数 ↑ 返回值
// 可以同时访问!
if (new) // 检查克隆是否成功
return track_skb_clone(old, new); // 建立 old → new 的追踪关系
return BPF_OK;
}
fentry_tc
TC BPF 程序不是内核函数,而是用户加载的 eBPF 程序, 它在网络栈中有两个关键执行点:
Ingress (入向):
网卡硬件 → netif_receive_skb() → TC BPF (ingress) → 网络协议栈
Egress (出向):
网络协议栈 → dev_queue_xmit() → TC BPF (egress) → 网卡硬件
由于 kprobe 只能附加到内核函数, 因此 pwru 使用了一种动态发现的方式添加到已有的 tc BPF程序上.
// internal/pwru/tracing.go:151-168
func TraceTC(coll *ebpf.Collection, spec *ebpf.CollectionSpec, opts *ebpf.CollectionOptions) *tracing {
log.Printf("Attaching tc-bpf progs...\n")
// 1. 扫描系统中所有 TC BPF 程序
progs, err := listBpfProgs(ebpf.SchedCLS)
if err != nil {
log.Fatalf("failed to list tc-bpf progs: %v", err)
}
var t tracing
t.progs = progs
// 2. 对每个发现的 TC BPF 程序附加 fentry 探测点
if err := t.trace(coll, spec, opts, progs, "fentry_tc"); err != nil {
log.Fatalf("failed to trace TC progs: %v", err)
}
return &t
}
使用了 fentry_tc 后, 处理流程变为:
用户包处理流程:
↓
TC 框架调用用户 BPF 程序
↓
fentry_tc 触发 (pwru 追踪逻辑)
↓
用户 TC BPF 程序执行 (分类、过滤、修改包等)
↓
包继续处理或被丢弃
fentry_xdp 和 fexit_xdp
XDP 是 Linux 内核中最早的包处理点,位于网络栈的最底层:
网卡硬件 → 网卡驱动 → XDP BPF 程序 → netif_receive_skb() → 协议栈
↑ ↑ ↑
DMA接收 最早处理点 常规网络栈
XDP 程序不能被 kprobe 追踪的原因和 tc BPF 一样: XDP 程序是用户加载的 eBPF 程序,不是内核函数
fentry_xdp 的作用机制是在 XDP 程序入口进行记录.
SEC("fentry/xdp")
int BPF_PROG(fentry_xdp, struct xdp_buff *xdp) {
struct event_t event = {};
u64 xdp_dhs = (u64) BPF_CORE_READ(xdp, data_hard_start);
if (cfg->is_set) {
// 1. 检查是否是从 SKB 转换而来的 XDP
if (cfg->track_skb && bpf_map_lookup_elem(&xdp_dhs_skb_heads, &xdp_dhs)) {
bpf_map_delete_elem(&xdp_dhs_skb_heads, &xdp_dhs);
goto cont;
}
// 2. 应用 XDP 层的过滤器
if (filter_xdp(xdp)) {
goto cont;
}
return BPF_OK;
cont:
// 3. 收集 XDP 层的元数据
set_xdp_output(ctx, xdp, &event);
}
// 4. 记录 XDP 事件
event.type = EVENT_TYPE_XDP;
event.skb_addr = (u64) &xdp; // XDP buff 地址
bpf_map_push_elem(&events, &event, BPF_EXIST);
return BPF_OK;
}
static __always_inline bool filter_xdp(struct xdp_buff *xdp) {
// 1. PCAP 过滤器(处理原始包数据)
void *data = (void *)(long) BPF_CORE_READ(xdp, data);
void *data_end = (void *)(long) BPF_CORE_READ(xdp, data_end);
if (!filter_pcap_ebpf_l2((void *)xdp, (void *)xdp, (void *)xdp, data, data_end))
return false;
// 2. 网络命名空间过滤
if (cfg->netns && BPF_CORE_READ(xdp, rxq, dev, nd_net.net, ns.inum) != cfg->netns)
return false;
// 3. 网卡接口过滤
if (cfg->ifindex && BPF_CORE_READ(xdp, rxq, dev, ifindex) != cfg->ifindex)
return false;
return true;
}
fexit_xdp 的作用是 skb buff 与 xdp buff 的联系
SEC("fexit/xdp")
int BPF_PROG(fexit_xdp, struct xdp_buff *xdp) {
u64 xdp_dhs = (u64) BPF_CORE_READ(xdp, data_hard_start);
// 记录 XDP buffer 的 data_hard_start 地址
// 用于后续与 SKB 建立关联
bpf_map_update_elem(&xdp_dhs_skb_heads, &xdp_dhs, &xdp, BPF_ANY);
return BPF_OK;
}
如果一个包最终进入协议栈 (用户XDP程序返回 XDP_PASS), 则处理流程如下:
1. 包到达网卡
↓
2. fentry_xdp 触发
└─ 应用过滤器,记录 XDP 事件
└─ 记录 data_hard_start 到 xdp_dhs_skb_heads
↓
3. XDP 程序执行 (用户程序)
↓
4. fexit_xdp 触发
└─ 更新 xdp_dhs_skb_heads 映射
↓
5. XDP_PASS: 转换为 SKB
↓
6. netif_receive_skb (kprobe 追踪)
└─ 检查 data_hard_start 是否在 xdp_dhs_skb_heads 中
└─ 如果在,说明这个 SKB 来自 XDP,建立关联追踪
如果是其他情况(XDP_DROP / XDP_TX / XDP_REDIRECT), 则流程如下:
1. 包到达网卡
↓
2. fentry_xdp 触发
└─ 应用过滤器,记录 XDP 事件
↓
3. XDP 程序执行
↓
4. XDP_DROP / XDP_TX / XDP_REDIRECT
└─ 包不进入网络栈,pwru 只能在 XDP 层看到
用户态程序
用户态程序的入口在 main.go, 它是 pwru 的核心控制器,负责整个程序的生命周期管理。其架构可以分为几个主要阶段:
初始化阶段 → BTF 处理阶段 → 后端选择阶段 → 函数发现阶段 → eBPF 准备阶段 → 动态代码注入阶段 → eBPF 配置和加载阶段 → 探测点附加阶段 → 事件处理阶段
初始化阶段
初始化阶段主要做了命令行参数处理, 最重要的是接收用户设置的过滤条件.
BTF 处理阶段
pwru 的核心功能是追踪网络包,它需要找到所有处理 sk_buff 的内核函数, 并且知道sk_buff* 参数在第几个位置
// internal/pwru/utils.go
func GetFuncs(pattern string, spec *btf.Spec, kmods []string, kprobeMulti bool) (Funcs, error) {
// 遍历 BTF 中的所有函数
iter := spec.Iterate()
for iter.Next() {
typ := iter.Type
fn, ok := typ.(*btf.Func)
if !ok {
continue
}
// 检查函数参数
fnProto := fn.Type.(*btf.FuncProto)
for i, param := range fnProto.Params {
// 查找 sk_buff* 参数在第几个位置
if isSkbParam(param.Type) {
funcs[fn.Name] = FuncInfo{
ArgPos: i + 1, // 参数位置
// ...
}
break
}
}
}
}
还有就是不同版本内核的sk_buff会发生变化(字段修改), 如果没有 BTF,相同的 pwru 二进制无法在不同内核版本上工作
// pwru 的 eBPF 代码使用 CO-RE 宏
u32 netns = BPF_CORE_READ(skb, dev, nd_net.net, ns.inum);
// ↑
// CO-RE 会根据 BTF 信息自动计算正确的偏移
后端选择阶段
这里是指 kprobe 和 kprobe-multi 之间的选择, kprobe-multi 性能更好, 但只在新的内核支持
var useKprobeMulti bool
if flags.Backend == "" {
// 自动选择:检查内核支持情况
useKprobeMulti = pwru.HaveBPFLinkKprobeMulti() && pwru.HaveAvailableFilterFunctions()
} else if flags.Backend == pwru.BackendKprobeMulti {
useKprobeMulti = true
}
函数发现阶段
pwru 完成以下工作:
- 解析内核的 BTF 信息
- 查找所有接受 sk_buff* 参数的函数
- 与 /sys/kernel/tracing/available_filter_functions 交集
- 返回可以被探测的函数列表
funcs, err := pwru.GetFuncs(flags.FilterFunc, btfSpec, flags.KMods, useKprobeMulti)
eBPF 程序准备阶段
bpfSpec, err := LoadKProbePWRU() // 从嵌入的字节流加载
LoadKProbePWRU() 是通过 bpf2go 工具生成的函数,它将编译好的 eBPF 程序嵌入到 Go 二进制中.
// build.go 第5行
//go:generate go run github.com/cilium/ebpf/cmd/bpf2go -target $TARGET_GOARCH -cc clang -no-strip KProbePWRU ./bpf/kprobe_pwru.c -- -I./bpf/headers -Wno-address-of-packed-member
当运行 go generate 时,会生成类似 kprobepwru_
func LoadKProbePWRU() (*ebpf.CollectionSpec, error) {
reader := bytes.NewReader(_KProbePWRUBytes)
spec, err := ebpf.LoadCollectionSpecFromReader(reader)
if err != nil {
return nil, fmt.Errorf("can't load KProbePWRU: %w", err)
}
return spec, err
}
......
var _KProbePWRUBytes []byte
动态代码注入阶段
先跳过特殊程序
switch name {
case "kprobe_skb_lifetime_termination",
"fexit_skb_clone",
"fexit_skb_copy",
"kprobe_veth_convert_skb_to_xdp_buff",
"kretprobe_veth_convert_skb_to_xdp_buff",
"fexit_xdp":
continue // 这些程序不需要注入过滤器
XDP 程序特殊处理
case "fentry_xdp":
// XDP 使用 L2 过滤器(以太网帧级别)
if err := libpcap.InjectL2Filter(program, flags.FilterPcap); err != nil {
log.Fatalf("Failed to inject filter ebpf for %s: %v", name, err)
}
// 注入 XDP 表达式过滤器
if err := pwru.InjectFilterXdpExpr(program, btfSpec, flags.FilterXdpExpr); err != nil {
log.Fatalf("Failed to inject filter xdp expr for %s: %v", name, err)
}
最后是常规 SKB 程序处理
// 注入 pcap 过滤器(L2、L3、隧道)
if err = libpcap.InjectFilters(program,
flags.FilterPcap, // 主要 pcap 过滤器
flags.FilterTunnelPcapL2, // 隧道 L2 过滤器
flags.FilterTunnelPcapL3); err != nil { // 隧道 L3 过滤器
log.Fatalf("Failed to inject filter ebpf for %s: %v", name, err)
}
// 注入 SKB 表达式过滤器
if err := pwru.InjectFilterSkbExpr(program, btfSpec, flags.FilterSkbExpr); err != nil {
log.Fatalf("Failed to inject filter skb expr for %s: %v", name, err)
}
// 注入元数据提取逻辑
if err := pwru.InjectSetSkbMetadata(program, skbMds); err != nil {
log.Fatalf("Failed to inject skb metadata for %s: %v", name, err)
}
动态注入原理
pwru 使用了一套非常巧妙的运行时代码生成机制,实现了从用户输入的 tcpdump 过滤表达式到高性能 eBPF 字节码的动态转换。整个过程分为以下几个阶段:
- 占位符函数设计(C 代码中的 Stub)
在 bpf/kprobe_pwru.c 中,定义了多个占位符函数:
// 占位符函数 - L2 层过滤
static __noinline bool
filter_pcap_ebpf_l2(void *_skb, void *__skb, void *___skb, void *data, void* data_end)
{
// 这是一个简单的占位符逻辑,总是返回 true
return data != data_end && _skb == __skb && __skb == ___skb;
}
// 占位符函数 - L3 层过滤
static __noinline bool
filter_pcap_ebpf_l3(void *_skb, void *__skb, void *___skb, void *data, void* data_end)
{
// 同样的占位符逻辑
return data != data_end && _skb == __skb && __skb == ___skb;
}
//...
__noinline 确保这些函数不会被内联,从而在 eBPF 字节码中保持独立的符号。
_skb、__skb、___skb:三个虚拟参数,为真实的过滤代码预留寄存器 R1、R2、R3
data:指向数据包起始位置(R4)
data_end:指向数据包结束位置(R5)
- Go 程序识别占位符
在internal/libpcap/inject.go 中,Go 程序扫描已编译的 eBPF 字节码:
func injectFilter(program *ebpf.ProgramSpec, filterExpr string, l3 bool, tunnel bool) error {
// 构造要查找的符号名
suffix := "_l2"
if l3 {
suffix = "_l3"
}
if tunnel {
suffix = "_tunnel" + suffix
}
// 在 eBPF 指令中查找占位符函数的位置
injectIdx := -1
for idx, inst := range program.Instructions {
if inst.Symbol() == "filter_pcap_ebpf"+suffix {
injectIdx = idx
break
}
}
if injectIdx == -1 {
return errors.New("Cannot find the injection position")
}
// ... 注入逻辑
}
- pcap 表达式编译流程
当用户输入 ‘dst host 115.238.126.36 and udp and dst port 9999’ 时,编译过程包含三个步骤:
步骤 3.1: tcpdump → cBPF (classic BPF)
func CompileCbpf(expr string, l3 bool) ([]bpf.Instruction, error) {
// 使用 libpcap 将 tcpdump 过滤表达式编译为 cBPF
pcap := C.pcap_open_dead(C.DLT_EN10MB, MAXIMUM_SNAPLEN) // L2 以太网
if l3 {
pcap = C.pcap_open_dead(C.DLT_RAW, MAXIMUM_SNAPLEN) // L3 IP 层
}
cexpr := C.CString(expr)
var bpfProg pcapBpfProgram
// 关键:调用 libpcap 的编译器
if C.pcap_compile(pcap, (*C.struct_bpf_program)(&bpfProg),
cexpr, 1, C.PCAP_NETMASK_UNKNOWN) < 0 {
return nil, fmt.Errorf("failed to pcap_compile '%s'", expr)
}
// 转换为 Go 的 bpf.Instruction 切片
// ...
}
步骤 3.2: cBPF → eBPF
func CompileEbpf(expr string, opts cbpfc.EBPFOpts, l3 bool) (asm.Instructions, error) {
// 先编译为 cBPF
cbpfInsts, err := CompileCbpf(expr, l3)
if err != nil {
return nil, err
}
// 使用 cloudflare/cbpfc 转换为 eBPF
ebpfInsts, err := cbpfc.ToEBPF(cbpfInsts, opts)
if err != nil {
return nil, err
}
// 调整 eBPF 指令以符合内核验证器要求
return adjustEbpf(ebpfInsts, opts)
}
步骤 3.3: 内核验证器兼容性调整:
由于 eBPF 验证器不允许直接内存访问,需要将所有内存读取转换为 bpf_probe_read_kernel 调用:
func adjustEbpf(insts asm.Instructions, opts cbpfc.EBPFOpts) (asm.Instructions, error) {
for idx, inst := range insts {
if inst.OpCode.Class().IsLoad() {
// 将 "r0 = *(u8 *)(r4 + 0)" 转换为:
//
// 1. 保存寄存器状态
// asm.StoreMem(asm.RFP, R1Offset, asm.R1, asm.DWord),
// asm.StoreMem(asm.RFP, R2Offset, asm.R2, asm.DWord),
// asm.StoreMem(asm.RFP, R3Offset, asm.R3, asm.DWord),
// 2. 调用 bpf_probe_read_kernel
// asm.Mov.Reg(asm.R1, asm.RFP), // r1 = 栈顶
// asm.Add.Imm(asm.R1, int32(BpfReadKernelOffset)), // r1 = 栈顶-8
// asm.Mov.Imm(asm.R2, int32(inst.OpCode.Size().Sizeof())), // r2 = 读取大小
// asm.Mov.Reg(asm.R3, inst.Src), // r3 = 源地址
// asm.Add.Imm(asm.R3, int32(inst.Offset)), // r3 += 偏移
// asm.FnProbeReadKernel.Call(), // 调用内核函数
// 3. 从栈读取结果
// asm.LoadMem(inst.Dst, asm.RFP, BpfReadKernelOffset, inst.OpCode.Size()),
// 4. 恢复寄存器状态
// ...
}
}
}
- 运行时代码替换
func injectFilter(program *ebpf.ProgramSpec, filterExpr string, l3 bool, tunnel bool) error {
// ... 找到注入点 injectIdx ...
var filterEbpf asm.Instructions
if filterExpr == "__pwru_reject_all__" {
// 特殊情况:拒绝所有包,通过让 data = data_end 实现
filterEbpf = asm.Instructions{
asm.Mov.Reg(asm.R4, asm.R5), // data = data_end,使原始条件失败
}
} else {
// 编译用户的 pcap 表达式
filterEbpf, err = CompileEbpf(filterExpr, cbpfc.EBPFOpts{
PacketStart: asm.R4, // 数据包起始地址在 R4
PacketEnd: asm.R5, // 数据包结束地址在 R5
Result: asm.R0, // 结果存储在 R0
ResultLabel: "result" + suffix,
Working: [4]asm.Register{asm.R0, asm.R1, asm.R2, asm.R3}, // 可用工作寄存器
LabelPrefix: "filter" + suffix,
StackOffset: -int(AvailableOffset),
}, l3)
}
// 保持元数据一致性(用于跳转计算)
filterEbpf[0] = filterEbpf[0].WithMetadata(program.Instructions[injectIdx].Metadata)
program.Instructions[injectIdx] = program.Instructions[injectIdx].WithMetadata(asm.Metadata{})
// 执行替换:在占位符位置插入真实的过滤代码
program.Instructions = append(program.Instructions[:injectIdx],
append(filterEbpf, program.Instructions[injectIdx:]...)...,
)
return nil
}
总结上面的过程, 就是
用户输入: ./pwru 'dst host 115.238.126.36 and udp and dst port 9999'
┌────────────────────────────────────────────────────────────────┐
│ 第一阶段:C 代码预编译 │
├────────────────────────────────────────────────────────────────┤
│ bpf/kprobe_pwru.c │
│ ├── filter_pcap_ebpf_l2() { 占位符逻辑 } │
│ ├── filter_pcap_ebpf_l3() { 占位符逻辑 } │
│ ├── filter_pcap_ebpf_tunnel_l2() { 占位符逻辑 } │
│ └── filter_pcap_ebpf_tunnel_l3() { 占位符逻辑 } │
│ │
│ 通过 bpf2go 工具编译为 kprobepwru_x86_bpfel.go │
│ ├── _KProbePWRUBytes []byte // eBPF 字节码 │
│ └── _KProbePWRUProgramSpecs // 程序规格 │
└────────────────────────────────────────────────────────────────┘
↓
┌────────────────────────────────────────────────────────────────┐
│ 第二阶段:Go 程序运行时动态注入 │
├────────────────────────────────────────────────────────────────┤
│ main.go 中的处理流程: │
│ │
│ 1. 加载 eBPF 程序规格 │
│ program := _KProbePWRUProgramSpecs.KProbeSkb1 │
│ │
│ 2. 查找占位符符号 │
│ for inst := range program.Instructions { │
│ if inst.Symbol() == "filter_pcap_ebpf_l2" { │
│ injectIdx = idx // 找到注入点 │
│ } │
│ } │
│ │
│ 3. 编译用户过滤表达式 │
│ 'dst host 115.238.126.36 and udp and dst port 9999' │
│ ↓ libpcap │
│ cBPF 指令 (经典 BPF) │
│ ↓ cloudflare/cbpfc │
│ eBPF 指令 (扩展 BPF) │
│ ↓ adjustEbpf() │
│ 内核验证器兼容的 eBPF 指令 │
│ │
│ 4. 代码替换 │
│ program.Instructions[injectIdx] 被替换为编译后的过滤代码 │
│ │
│ 5. 加载到内核 │
│ collection, err := ebpf.NewCollectionWithOptions( │
│ ebpf.CollectionSpec{Programs: programs}, opts) │
└────────────────────────────────────────────────────────────────┘
这种设计让 pwru 既拥有 eBPF 的高性能,又具备 tcpdump 过滤语法的易用性.
eBPF 配置和加载阶段
先获取内核结构体的 BTF ID,用于 bpf_snprintf_btf() 函数格式化输出
skbBtfID, err := pwru.GetStructBtfID(btfSpec, "sk_buff")
shinfoBtfID, err := pwru.GetStructBtfID(btfSpec, "skb_shared_info")
再进行配置注入:
pwruConfig, err := pwru.GetConfig(&flags)
pwruConfig.SkbBtfID = uint32(skbBtfID)
pwruConfig.ShinfoBtfID = uint32(shinfoBtfID)
// 将配置写入 eBPF 程序的全局变量
if err := bpfSpec.Variables["CFG"].Set(pwruConfig); err != nil {
log.Fatalf("Failed to rewrite config: %v", err)
}
最后加载 eBPF 程序
var opts ebpf.CollectionOptions
opts.Programs.KernelTypes = btfSpec
opts.Programs.LogLevel = ebpf.LogLevelInstruction
coll, err := ebpf.NewCollectionWithOptions(bpfSpec, opts)
这里将所有 eBPF 程序加载到内核中,包括:Maps(事件队列、追踪表等) 以及 Programs(各种探测点程序)
探测点附加阶段
- TC/XDP 追踪
动态发现并附加到系统中的 TC/XDP BPF 程序.
if flags.FilterTraceTc {
t := pwru.TraceTC(coll, bpfSpecFentryTc, &opts)
defer t.Detach()
traceTc = t.HaveTracing()
}
if flags.FilterTraceXdp {
t := pwru.TraceXDP(coll, bpfSpecFentryXdp, &opts)
defer t.Detach()
traceXdp = t.HaveTracing()
}
- SKB 生命周期追踪
if flags.FilterTrackSkb || flags.FilterTrackSkbByStackid {
t := pwru.TrackSkb(coll, haveFexit, flags.FilterTrackSkb)
defer t.Detach()
}
3 非 SKB 函数追踪
if nonSkbFuncs := flags.FilterNonSkbFuncs; len(nonSkbFuncs) != 0 {
k := pwru.NewNonSkbFuncsKprober(nonSkbFuncs, funcs, coll)
defer k.DetachKprobes()
}
- 主要 kprobe 附加
if len(funcs) != 0 {
k := pwru.NewKprober(ctx, funcs, coll, addr2name, useKprobeMulti, flags.FilterKprobeBatch)
defer k.DetachKprobes()
}
事件处理阶段
最后的事件处理阶段就是不断从 Map 中读取事件, 然后输出.
- 输出准备
printSkbMap := coll.Maps["print_skb_map"]
printShinfoMap := coll.Maps["print_shinfo_map"]
printStackMap := coll.Maps["print_stack_map"]
output, err := pwru.NewOutput(&flags, printSkbMap, printShinfoMap, printStackMap, addr2name, skbMds, xdpMds, useKprobeMulti, btfSpec)
- 事件循环
var event pwru.Event
events := coll.Maps["events"] // BPF 事件队列
runForever := flags.OutputLimitLines == 0
for i := flags.OutputLimitLines; i > 0 || runForever; i-- {
for {
// 非阻塞读取事件
if err := events.LookupAndDelete(nil, &event); err == nil {
break
}
select {
case <-ctx.Done():
return // 接收到退出信号
case <-time.After(time.Microsecond):
continue // 短暂休眠后重试
}
}
// 输出事件
if flags.OutputJson {
output.PrintJson(&event)
} else {
output.Print(&event)
}
select {
case <-ctx.Done():
return
default:
}
}