跟我一起学习drgn(3)---调试crash dump

drng 可以调试运行中的 kernel (通过/proc/kcore), 也可以对 crash dump 文件进行调试.
本文以官网中的Kyber bug为例子, 介绍 drgn 如何找出内核 bug.
前置知识
为了读懂这个案例, 需要先了解一些前置知识。
内核会为每个 block 设备建立一个每 CPU 的 “software queue”, 并为硬件 I/O queue 建立一个 “hardware queue”,这两者是多对一的关系:
每一个”hardware queue”可以绑定一个或多个”software queue”.
与此同时, 内核还会为使用的 I/O调度器 (如本例中的 Kyber) 创建一些额外数据, 保存到 “hardware queue” 的数据结构中
下图展示了一个绑定了2个”software queue”的”hardware queue”:
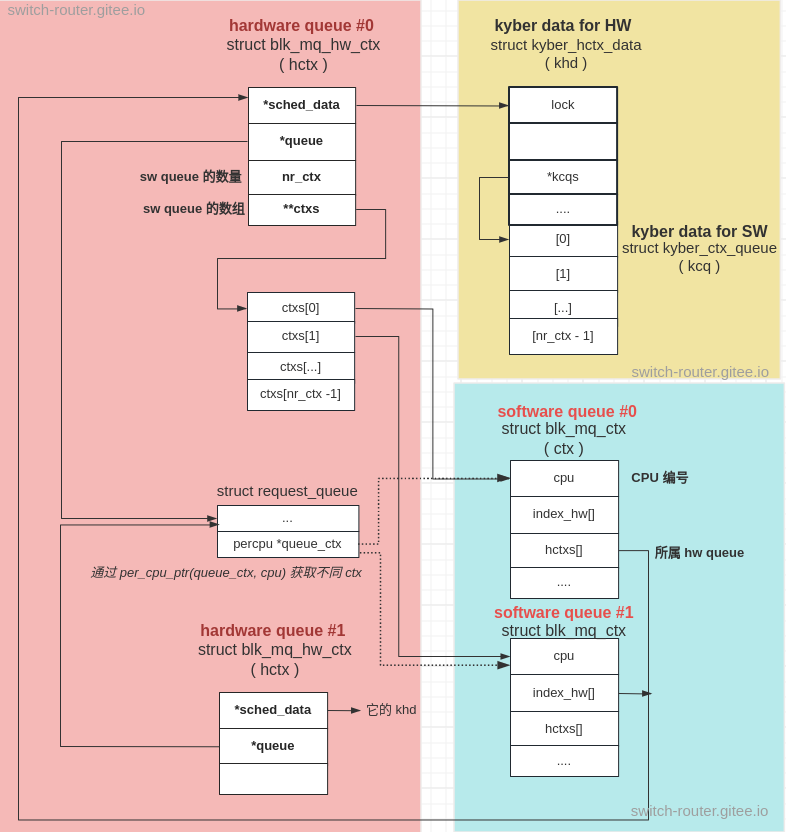
其中 hctx 对应 “hardware queue”, ctx 对应 “software queue”, khd和kcq对应额外数据.
另外, 需要注意的还有 2 点:
struct request_queue结构中的 percpu 变量queue_ctx, 指定不同的 cpu 可以得到不同的ctx.- 额外数据部分, SW 的额外数据(
kcq)在内存布局上紧跟 HW 的额外数据(khd).
bug 定位
使用 drgn 指定 crash dump 文件进入交互模式后, 我们首先找到发生 crash 的 task
task = per_cpu(prog["runqueues"], prog["crashing_cpu"]).curr
然后, 使用 Helper 函数 stack_trace 得到出问题的堆栈:
>>> trace = prog.stack_trace(task)
>>> trace
#0 queued_spin_lock_slowpath (../kernel/locking/qspinlock.c:471:3)
#1 queued_spin_lock (../include/asm-generic/qspinlock.h:85:2)
#2 do_raw_spin_lock (../kernel/locking/spinlock_debug.c:113:2)
#3 spin_lock (../include/linux/spinlock.h:354:2)
#4 kyber_bio_merge (../block/kyber-iosched.c:573:2)
#5 blk_mq_sched_bio_merge (../block/blk-mq-sched.h:37:9)
#6 blk_mq_submit_bio (../block/blk-mq.c:2182:6)
#7 __submit_bio_noacct_mq (../block/blk-core.c:1015:9)
#8 submit_bio_noacct (../block/blk-core.c:1048:10)
#9 submit_bio (../block/blk-core.c:1125:9)
#10 submit_stripe_bio (../fs/btrfs/volumes.c:6553:2)
#11 btrfs_map_bio (../fs/btrfs/volumes.c:6642:3)
#12 btrfs_submit_data_bio (../fs/btrfs/inode.c:2440:8)
#13 submit_one_bio (../fs/btrfs/extent_io.c:175:9)
#14 submit_extent_page (../fs/btrfs/extent_io.c:3229:10)
#15 __extent_writepage_io (../fs/btrfs/extent_io.c:3793:9)
#16 __extent_writepage (../fs/btrfs/extent_io.c:3872:8)
#17 extent_write_cache_pages (../fs/btrfs/extent_io.c:4514:10)
#18 extent_writepages (../fs/btrfs/extent_io.c:4635:8)
#19 do_writepages (../mm/page-writeback.c:2352:10)
#20 __writeback_single_inode (../fs/fs-writeback.c:1467:8)
#21 writeback_sb_inodes (../fs/fs-writeback.c:1732:3)
#22 __writeback_inodes_wb (../fs/fs-writeback.c:1801:12)
#23 wb_writeback (../fs/fs-writeback.c:1907:15)
#24 wb_check_background_flush (../fs/fs-writeback.c:1975:10)
#25 wb_do_writeback (../fs/fs-writeback.c:2063:11)
#26 wb_workfn (../fs/fs-writeback.c:2091:20)
#27 process_one_work (../kernel/workqueue.c:2275:2)
#28 worker_thread (../kernel/workqueue.c:2421:4)
#29 kthread (../kernel/kthread.c:292:9)
#30 ret_from_fork+0x1f/0x2a (../arch/x86/entry/entry_64.S:294)
从堆栈信息看, 最终内核是 crash 在自旋锁的调用中,而我们有理由假设自旋锁本身实现没有问题 (毕竟它是内核非常’基础’的实现),
那么问题大概率就发生在调用者kyber_bio_merge()中:
static bool kyber_bio_merge(struct blk_mq_hw_ctx *hctx, struct bio *bio,
unsigned int nr_segs)
{
struct kyber_hctx_data *khd = hctx->sched_data;
struct blk_mq_ctx *ctx = blk_mq_get_ctx(hctx->queue); // 获取当前 cpu 的 ctx
struct kyber_ctx_queue *kcq = &khd->kcqs[ctx->index_hw[hctx->type]];
unsigned int sched_domain = kyber_sched_domain(bio->bi_opf);
struct list_head *rq_list = &kcq->rq_list[sched_domain];
bool merged;
spin_lock(&kcq->lock); // <------- crash here
merged = blk_bio_list_merge(hctx->queue, rq_list, bio, nr_segs);
spin_unlock(&kcq->lock);
return merged;
}
这里 kyber_bio_merge() 对&kcq->lock进行上锁, 既然在这里出问题,那么很可能就是&kcq->lock的内存压根不是一个有效的自旋锁.
有了这个怀疑目标, 下面我们就使用 drgn 对照数据结构看看哪里出问题了:
>>> trace[4]["khd"]
(struct kyber_hctx_data *)<absent>
>>> hctx = trace[4]["hctx"]
>>> khd = cast("struct kyber_hctx_data *", hctx.sched_data)
>>> trace[4]["kcq"] - khd.kcqs
(ptrdiff_t)1
>>> hctx.nr_ctx
(unsigned short)1
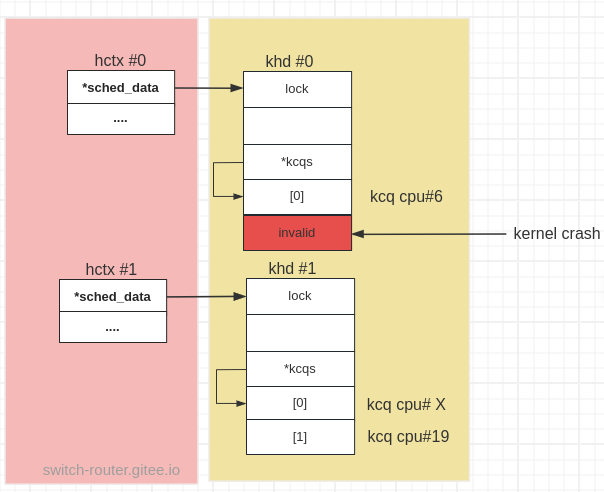
trace[4]["kcq"] - khd.kcqs的结果(ptrdiff_t)1表示这个kcq与khd间隔了一个单位的kcq大小的内存, 因此这个kcq是第2个 “software queue”
但hctx.nr_ctx的结果(unsigned short)1 表明这个 “hardware queue” 只绑定了 1 个”software queue”, 根本不会有第2个kcq.
来看看这个kcq对应的 cpu:
>>> hctx.ctxs[0].cpu
(unsigned int)6
但 crashing_cpu 的值表示, crash 是发生在 cpu 19.
prog["crashing_cpu"]
(int)19
我们再来看下函数 kyber_bio_merge() 的调用者:
bool __blk_mq_sched_bio_merge(struct request_queue *q, struct bio *bio,
unsigned int nr_segs)
{
struct elevator_queue *e = q->elevator;
struct blk_mq_ctx *ctx = blk_mq_get_ctx(q); // 获取当前 cpu 对应的 ctx
struct blk_mq_hw_ctx *hctx = blk_mq_map_queue(q, bio->bi_opf, ctx); // 获取 ctx 所属的 hctx
...
if (e && e->type->ops.bio_merge)
return e->type->ops.bio_merge(hctx, bio, nr_segs);
...
}
这里获取了当前 cpu 对应的ctx,以及ctx所属的hctx, 并将后者作为参数传入 kyber_bio_merge()
到这里, 问题原因就呼之欲出了,kyber_bio_merge由于抢占的原因, 从 cpu 6 迁移到另一个cpu 19:
这样导致在kyber_bio_merge里,ctx和hctx是不匹配的.
cpu 6 cpu 19
__blk_mq_sched_bio_merge
|
|-- ctx = blk_mq_get_ctx(q)
|-- __blk_mq_get_ctx(q, raw_smp_processor_id());
|-- hctx = blk_mq_map_queue(q, bio->bi_opf, ctx)
|
|-- kyber_bio_merge(hctx, ....)
------------------------------ preempt ---------------------------------
kyber_bio_merge(hctx, ...)
|
|-- ctx = blk_mq_get_ctx(hctx->queue)
|-- __blk_mq_get_ctx(q, raw_smp_processor_id());
|-- kcq = &khd->kcqs[ctx->index_hw[hctx->type]]
cpu 6 对应的 kcq 所属的hctx只有绑定了 1 个kcq, 但迁移到 cpu 19 时, 由于重新获取了ctx (该ctx所属的hctx已经不是传入的hctx了)
内存地址&khd->kcqs[ctx->index_hw[hctx->type]]上不是一个有效的 kcq, 对其自旋锁上锁最终 crash.
修复 bug 的 commit 在这里, 修复的思想就是始终保持 hctx 和 ctx 的匹配.