dlmalloc 原理分析
简介
dlmalloc 全称是 Doug Lea’s Malloc, 它是由 Doug Lea 开发的经典 memory allocator, 被广泛运用在其他开源软件或库, 如 VPP、SQLite、uClibc、RT-Thread 等.
从实践上看, 它具有以下优点:
-
多线程无锁分配: 它通过线程本地存储(TLS)或私有堆(per-thread-heap)实现完全无锁分配.
-
元数据开销最小化: 它的元数据结构十分简洁, 额外开销甚少, 非常适合应用于资源受限环境.
-
低碎片化: 它允许更细粒度的内存块分割和合并策略,尤其在小内存块的管理上更高效
-
减少系统调用: 它预分配大块内存池,后续所有分配均在用户态完成,无需内核介入.
作者在 https://gee.cs.oswego.edu/dl/html/malloc.html 描述了写 dlmalloc 的动机, 以及心目中优秀的 memory allocator 的目标如下:
- Maximizing Compatibility 最大化兼容性
它应该与其他软件兼容, 尤其应该遵守 ANSI/POSIX 标准
- Maximizing Portability 最大化可移植性
它应该尽可能少依赖系统特性(如系统调用),同时仍为某些系统独有的有用功能提供可选支持;并符合所有已知的系统对齐和寻址规则.
解释一下就是: 设计中应该减少对特定系统调用或API的依赖, 因为这些依赖可能导致代码在其他平台上无法运行。例如,使用POSIX标准的函数而不是Windows特有的API,或者使用抽象层来封装系统相关的代码
另一方面,虽然要减少依赖,但某些功能可能只在特定系统上存在且非常有用,因此需要以可选的方式支持它们。
比如,在 Linux 上使用 epoll 进行高效 I/O 复用,而在 Windows 上使用 IOCP,但通过条件编译或插件机制来提供这些功能。
另外, 不同硬件架构(如x86、ARM)有不同的内存对齐要求和寻址限制。代码需要遵守这些规则以避免崩溃或性能下降,比如确保数据结构正确对齐,或处理不同字节序的问题
- Minimizing Space 最小化空间
它应该不浪费空间, 应该尽可能少地从系统获取内存, 并始终应该让碎片内存尽可能地少.
- Minimizing Time 最小化时间
它的 malloc()\free()\realloc() 等实现应该尽可能地小耗时短, 或者说可控。
- Maximizing Tunability 最大化可调整性
它的可选功能和行为应由用户静态(通过宏定义等) 或动态(通过控制命令,例如 mallopt)控制, 方便用户定制出最合适的配置。
- Maximizing Locality 最大化局部性
它分配大内存时应该尽可能靠近, 因为计算机系统中短时间内倾向于重复访问某些数据或相邻数据, 这有助于减少程序运行期间出现缺页和cache miss
- Maximizing Error Detection 最大化错误检测
它应该可以检测明显的踩内存、重复释放问题。
- Minimizing Anomalies 最小化异常
即使是使用默认配置, 它也应该在大部分程序上表现良好。
以上准则有些优点拗口, 接下来, 我将从源码角度对 dlmalloc 展开分析.
源码地址: https://github.com/switch-router-nat/dlmalloc
总览
整个源码仅2个文件: dlmalloc.c 和 dlmalloc.h, 这个特点使其非常容易被集成到其他代码里.
其中 dlmalloc.h 主要放着注释和函数声明. 其中包含一些”术语”的定义, 包括各个宏开关的解释和默认值.
这里面最重要我觉得是 MSPACES (Memory Spaces), 它可以类比于 linux kernel 中的 namespace 的概念. 一旦使能了, 就会衍生出 mspace_malloc(), mspace_free() 等函数, 这些函数相比原版会多一个额外的 mspace 参数.
If MSPACES is defined, then in addition to malloc, free, etc., this file also defines mspace_malloc, mspace_free, etc. These are versions of malloc routines that take an “mspace” argument obtained using create_mspace, to control all internal bookkeeping.
而这可以让一个程序中创建多个 mspace 空间, 它们使用互不重叠的内存.
相反, 如果不使能 MSPACES , 则相当于是使用默认唯一的空间. 至于该文件中的其他定义, 可以遇到了再来查询.
接下来是 dlmalloc.c, 该文件包含了 dlmalloc 的具体实现, 下面我们就进入该文件.
mspace 和 mstate
如果使能了MSPACES, 应用程序要做的第一件事就是 创建mspace
typedef void* mspace;
typedef struct malloc_state* mstate;
...
mspace create_mspace(size_t capacity, int locked) {
mstate m = 0;
size_t msize;
ensure_initialization();
msize = pad_request(sizeof(struct malloc_state));
if (capacity < (size_t) -(msize + TOP_FOOT_SIZE + mparams.page_size)) {
size_t rs = ((capacity == 0)? mparams.granularity :
(capacity + TOP_FOOT_SIZE + msize));
size_t tsize = granularity_align(rs);
char* tbase = (char*)(CALL_MMAP(tsize));
if (tbase != CMFAIL) {
m = init_user_mstate(tbase, tsize); // --> 初始化 mstate
m->seg.sflags = USE_MMAP_BIT;
set_lock(m, locked);
}
}
return (mspace)m;
}
上面的函数创建一个指定capacity大小内存的mspace, 其内部最重要的就是调用 init_user_mstate() 初始化mstate
这里的mstate相当于作为这块内存区域的元数据, 它位于申请内存的顶部, 记录整个内存的使用情况.
这里的capacity是纯用户可用的内存大小, 不不含元数据自身所占的内存空间. 因此这个函数实际从操作系统申请的内存是要超过capacity的。
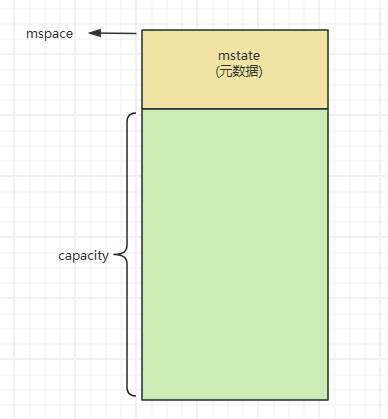
如上图所示, 在整个 mspace 内存空间里, 元数据控制结构位于顶端, 余下的一大片都是待分配给应用程序的内存.
chunk
对于使能了MSPACES版本来说, 应用程序调用下面这个API, 从指定的mspace内部申请bytes字节内存
/* 从 msp 指定的 mspace 申请分配 bytes 字节长度的内存 */
void* mspace_malloc(mspace msp, size_t bytes)
分配内存的单元被称为 chunk, 其大小并不固定, 应用程序申请的内存越大, chunk 所占的内存也就越多。
chunk 中除了包含真正提供给应用程序的内存空间外, 还要记录该内存空间长度, 因为当应用程序释放内存时, 只会提供首地址, 并不会提供长度.
正在被使用的 chunk 在内存中的布局如下 (每一行代表8个字节):
如果 prev chunk 处于被使用状态:
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| payload of previous chunk |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of this chunk |C|P| C = 1 P = 1
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+- +
| |
+- +
| :
+- size - sizeof(size_t) available payload bytes +
: |
chunk-> +- +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk (may or may not be in use) |C|P| C = 0/1 P = 1
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
如果 prev chunk 处于空闲状态:
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of this chunk |C|P| C = 1 P = 0
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+- +
| |
+- +
| :
+- size - sizeof(size_t) available payload bytes +
: |
chunk-> +- +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk (may or may not be in use) |C|P| C = 0/1 P = 1
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
关于 chunk 的布局, 有几点需要解释:
- chunk 与 chunk 之间在内存中紧密相连;
- chunk 在内存中 16 字节对齐, chunk 的第二行除了表示该 chunk 大小外, 未使用的低 2 比特 C 和 P 是两个标记位, 分别表示 current chunk 和 previous chunk 是否正在被使用;
- chunk 指针指向的前 8 字节内存其实还属于 previous chunk;
- 如果 previous chunk 处于使用状态, 这 8 个字节就是属于 previous chunk 的 payload 内存
- 如果 previous chunk 处于空闲状态, 这 8 个字节则记录 previous chunk 的大小
- mem 指针是实际返回给应用程序的内存首地址
- 应用程序能实际读写的内存的尾部已经侵入到 next chunk
而如果 current chunk 处于空闲状态, 则内存布局如下:
chunk-> +- -+
| User payload (must be in use, or we would have merged!) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of this chunk |C|P| C = 0 P = 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Next pointer |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Prev pointer |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| :
+- size - sizeof(struct chunk) unused bytes +
: |
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of this chunk |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk (must be in use) |C|P| C = 1 P = 0
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| :
+- User payload +
: |
同样有几点需要解释:
- 空闲 chunk 的 previous chunk 一定正在使用 (P = 1), 否则两个连续空闲的 chunk 会被合并为一个. next chunk 同理.
- chunk 指针的第3行和第4行分别为指向其他 chunk 的指针. 这一点稍后在 smallbin 中阐述.
回过头再看看代码里 chunk 的定义:
struct malloc_chunk {
size_t prev_foot; /* Size of previous chunk (if free). */
size_t head; /* Size and inuse bits. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
};
top chunk
top chunk是一个 mspace 中一个特殊的 chunk. 它是该 mspace 的最后分配源. 初始状态下, top chunk几乎表示了整个待分配内存。
若应用程序申请的内存现有空闲 chunk 都不满足, dlmalloc会从 top chunk 中切分出一个 chunk, 剩余部分仍作为 top chunk 保留;
当释放的内存块与 top chunk 相邻时,dlmalloc 会将其合并到 top chunk 中. top chunk 的大小和位置会记录在 mspace 的元数据中。
以一个 capacity = 4096 的 mspace 为例, 初始状态下, top chunk 的内存布局如下图所示 (水平线表示重叠的内存地址):
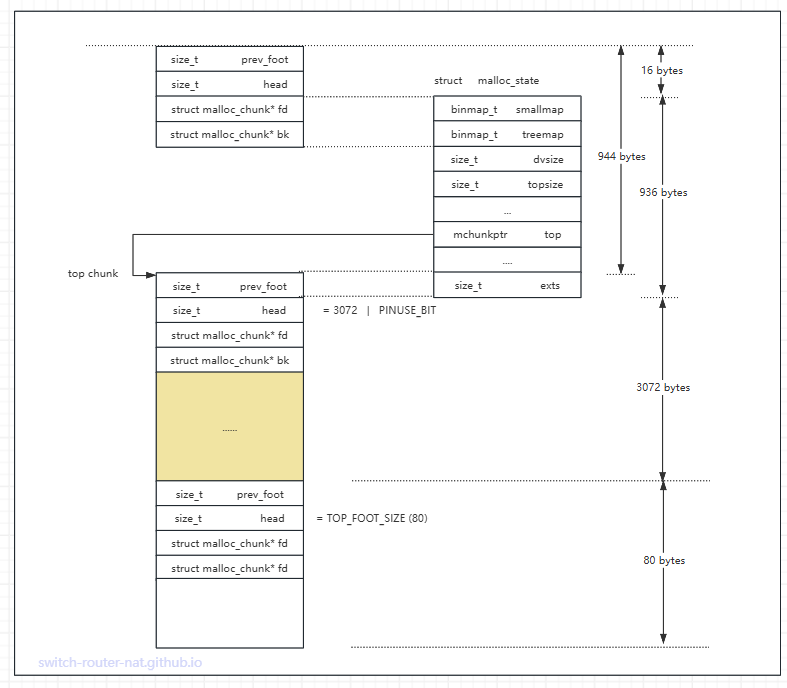
如果此时程序申请一个 24 字节内存, 那么 top chunk 将向下移动 32 字节 (申请字节数+8, 再16字节对齐)
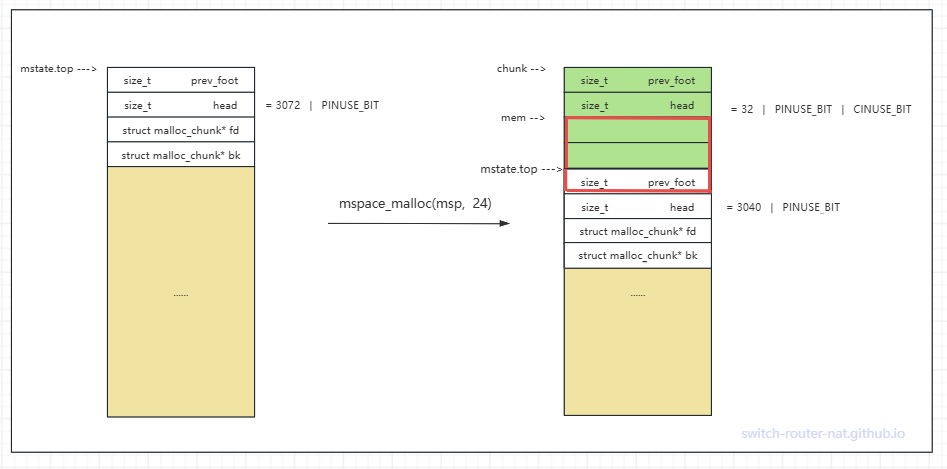
图中mem为返回给应用程序的地址, 红框为用户可读写的内存.
smallbin
smallbin 是用于管理较小的 chunk 的核心数据结构, 它位于 mspace 的元数据struct malloc_state结构中, 通过固定大小的双向链表组织空闲内存块,优化小内存的分配和释放效率.
这里的较小是指用户申请的内存大小不超过 232 Bytes, 对应此时 chunk 大小为 240 Bytes (用户申请内存加 8 Bytes,再 16 Bytes 对齐)
smallbin 包含了若干 chunk 链表, 每个链表串联起相同大小的 chunk, 链表之间间隔为 8 Bytes.
链表1 <--> 32 Bytes chunk <--> 32 Bytes chunk <--> 32 Bytes chunk
链表2 <--> 40 Bytes chunk <--> 40 Bytes chunk <--> 40 Bytes chunk
链表3 <--> 48 Bytes chunk <--> 48 Bytes chunk <--> 48 Bytes chunk
...
链表27 <--> 240 Bytes chunk <--> 240 Bytes chunk <--> 240 Bytes chunk
链表上的 chunk 通常是由于程序释放, 并且又不能与上下相邻的 chunk 合并产生的.
如下图所示, 展示了 32 Bytes 大小的 chunk 链表, 它将内存区中游离的所有 32 Bytes chunk 串联了起来.
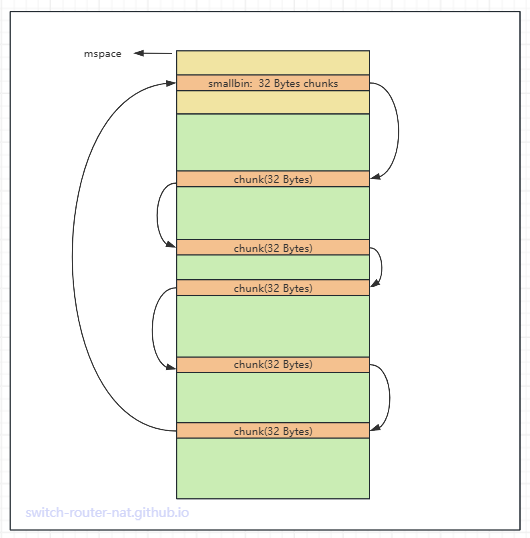
从代码上看, mspace 元数据内有两个字段与 smallbin 有关: smallmap和smallbins
struct malloc_state {
binmap_t smallmap;
...
mchunkptr smallbins[(NSMALLBINS+1)*2]; // NSMALLBINS = 32
...
};
其中,smallbins就是上面提到的链表数组, 而 smallmap 则是一个 bitmap, 每一位用来表示是否存在对应大小的空闲 small chunk, 比如若存在一个大小为 32 Bytes 的 chunk, 则 smallmap 的第 32 » 3 = 4 (下标从0开始) 位会被置位。
smallbins 有 (32+1)*2 = 66 个元素, 其中每 2 个为一组(fd 和 bk), 33 组比上面的 27 条链表要多, 这是由于有一些组不会使用, 因为 chunk 有最小大小的限制, 前几组元素并不会用到.
dlmalloc 对于小内存请求遵循以下顺序算法:
1. smallbin 里存在匹配的 **remainderless chunk** (指 chunk 的大小与请求完全匹配,分割后无剩余空间可形成新 chunk);
2. 从 dv chunk 分配 (通常为最近一次请求或释放形成的 chunk);
3. 从 smallbin 中选择最小的可用 chunk 进行分割,将剩余部分保存为新的 dv chunk;
4. 从 top chunk 分配;
5. 向操作系统申请新内存并使用.
dv chunk
dv(designated victim)是一种缓存机制,用于快速响应连续的小请求,减少对 smallbins 的遍历, 它产生于对 small chunk 的分割.
在一个 msapce 中, 只有唯一的 dv chunk, 它和 top chunk 一样, 保存在 mspace 的元数据中, 被 dv 保存的 chunk 不再会被 smallbin 跟踪.
每个 msapce 只能保存一个 dv chunk, 当有新的 chunk 产生需要保存为 dv chunk 时, 原 dv 会重新插入 smallbin
struct malloc_state {
...
mchunkptr dv;
mchunkptr top;
...
}
下面是一个产生 dv chunk 的例子:
mspace mymspace = create_mspace(0,0);
/* 请求第一个 128 字节内存空间的 chunk */
void* mem1 = mspace_malloc(mymspace, 128);
/* 请求第二个 128 字节内存空间的 chunk */
void* mem2 = mspace_malloc(mymspace, 128);
/* 释放第一个 chunk, 会产生一个 small chunk 加入 smallbin */
mspace_free(mymspace, mem1);
/* 请求一个较小的 chunk, 此时会分割刚刚的 small chunk, 余下部分会成为 dv chunk */
void* mem3 = mspace_malloc(mymspace, 64);
treebin
treebin是一种用于管理较大 chunk (不小于256 Bytes)的高效数据结构,它通过树的形式来组织空闲 chunk.
mspace 元数据中有两个字段与 treebin 有关:treemap和treebins. 其中 treebins 有 NSMALLBINS(32) 个 slot 用于存放不同范围的 chunk, 而 treemap 则用来快速检查对应 slot 是否有 chunk
struct malloc_state {
binmap_t treemap;
...
tbinptr treebins[NTREEBINS]; // NSMALLBINS = 32
...
};
struct malloc_tree_chunk {
/* The first four fields must be compatible with malloc_chunk */
size_t prev_foot;
size_t head;
struct malloc_tree_chunk* fd;
struct malloc_tree_chunk* bk;
struct malloc_tree_chunk* child[2];
struct malloc_tree_chunk* parent;
bindex_t index;
};
typedef struct malloc_tree_chunk tchunk;
typedef struct malloc_tree_chunk* tchunkptr;
typedef struct malloc_tree_chunk* tbinptr; /* The type of bins of trees */
treebin 根据索引I多个层级,每个层级对应一段大小范围, 每一层都是都是一棵独立的 tree. 要插入 treebin 的 chunk 根据其大小进入不同的层
计算方法如下, 其中S是 chunk 的大小(输入参数), I是层索引(输出参数)
#define compute_tree_index(S, I)\
{\
unsigned int X = S >> TREEBIN_SHIFT;\
if (X == 0)\
I = 0;\
else if (X > 0xFFFF)\
I = NTREEBINS-1;\
else {\
unsigned int K = (unsigned) sizeof(X)*__CHAR_BIT__ - 1 - (unsigned) __builtin_clz(X); \
I = (bindex_t)((K << 1) + ((S >> (K + (TREEBIN_SHIFT-1)) & 1)));\
}\
}
首先通过S向右移动8位,得到X, 由于按照设计S的最小值是256, 则正常情况下X的最小值为1.
一般情况(1 ≤ X ≤ 0xFFFF), 先计算K, 再计算I
_builtin_clz(X) 是 GCC 内置函数,返回 X 的二进制前导零(Leading Zeros)数量。
sizeof(X) * CHAR_BIT 是 unsigned int 的总位数, 一般为 32.
由此可以得到
K = (总位数 - 1) - 前导零数
示例1: 若 S = 1280 (X = 5, 二进制 010100000000),前导零数为29, 则K = 31 - 29 = 2
示例2: 若 S = 1536 (X = 6, 二进制 011000000000),前导零数为29, 则K = 31 - 29 = 2
计算I的步骤是:
(K << 1):将 K 乘以 2,生成一个基数
(S >> (K + TREEBIN_SHIFT - 1)) & 1:检查 S 的第 (K + 7) 位是否为 1(即下一个有效位)
即
I = 2*K + (下一个有效位)
示例1: 若 S = 1280, 由前面计算得到K = 2, 则K + 7 = 9, S >> 9 = 2(二进制10), 最低位为0. 最终I = 2*2 + 0 = 4
示例2: 若 S = 1536, 由前面计算得到K = 2, 则K + 7 = 9, S >> 9 = 3(二进制11), 最低位为1. 最终I = 2*2 + 1 = 5
因此, S大小和I的映射关系为
| chunk 大小(Byte) | K | I | chunk 分配策略 |
|---|---|---|---|
| [256, 511] | 0 | 0 或 1 | 根据第 7 位是否为1划分 |
| [512, 1023] | 1 | 2 或 3 | 根据第 8 位是否为1划分 |
| [1024, 2047] | 2 | 4 或 5 | 根据第 9 位是否为1划分 |
| … | … | … | … |
| [8M, 16M) | 15 | 30或31 | 根据第 22 位是否为1划分 |
而在一个层级内部的树状结构上, treebin 总是将较小的 chunk 放置在左子树, 较大的 chunk 放置在右子树.
dlmalloc 对于大内存请求遵循以下顺序算法:
1. 从 treebin 里找满足请求的 chunk
2. 从 dv chunk 分配
3. 从 top chunk 分配;
4. 向操作系统申请新内存并使用.