解析 bpfsnoop:现代化 eBPF 内核追踪工具
![]()
背景与技术演进
传统内核追踪的痛点
在 Linux 系统调试和性能分析领域,内核级追踪一直是开发者和运维工程师的重要工具。然而,传统的追踪技术存在诸多限制,严重影响了其在生产环境中的应用。
kprobe 作为 Linux 内核最早的动态追踪机制,其工作原理是在目标函数的入口点插入断点指令(INT3),当 CPU 执行到该指令时触发异常处理。这种机制虽然功能完备,但带来了显著的性能开销。
每次函数调用都会经历完整的异常处理流程(保存寄存器到栈->异常处理do_int3()->查找执行对应kprobe函数->恢复寄存器),对于高频调用的函数(如网络包处理、系统调用等),这种开销是无法接受的。
# 原始函数
tcp_connect:
push %rbp # 原始指令
mov %rsp,%rbp
...
# kprobe 激活后
tcp_connect:
int3 # 断点指令 (0xCC)
mov %rsp,%rbp # 原始指令被移位保存
...
eBPF 技术栈的革新
BPF Trampoline 是在 Linux 5.5 版本中引入的革命性特性,它彻底改变了 eBPF 程序的 attach 机制。与传统的断点方式不同,Trampoline 采用了直接函数调用的方式:
比如这里, 我们尝试 attach 到 tcp_connect 函数
# 原始函数入口(5字节 NOP 指令)
tcp_connect:
nop DWORD PTR [rax+rax*1+0x0] ; 5-byte NOP
push %rbp
mov %rsp,%rbp
...
# Trampoline 激活后
tcp_connect:
call bpf_trampoline_12345 ; 直接调用 BPF 程序
push %rbp
mov %rsp,%rbp
...
这种机制的优势包括:
- 零开销调用:没有异常处理,只是普通的函数调用
- 保持指令缓存:不破坏 CPU 的预取和缓存机制
- 寄存器传递:可以直接访问函数参数,无需从栈中读取
- 类型安全:通过 BTF 信息确保参数类型正确
性能对比数据显示,fentry/fexit 的调用开销通常只有 10-30 纳秒,相比 kprobe 有了数量级的提升
BTF
BTF(BPF Type Format) 是 Linux 4.18 引入的用于描述数据类型和函数签名的元数据格式。
它相当于内核数据结构的”调试符号”精简版,主要作用是为 eBPF 程序提供类型信息,让 eBPF 工具能够在运行时理解内核数据结构, 从而实现 eBPF CO-RE(Compile Once - Run Everywhere)
比如上面的tcp_connect例子, 我们使用 bpftool 工具可以从 vmlinux 找到其类型是 FUNC, 函数原型的 id 是 26236
$ bpftool btf dump file /sys/kernel/btf/vmlinux | grep -A 2 "tcp_connect"
[28726] FUNC 'mptcp_connect' type_id=28251 linkage=static
[28727] FUNC 'mptcp_ioctl' type_id=28235 linkage=static
[28728] FUNC_PROTO '(anon)' ret_type_id=28 vlen=2
--
[72693] FUNC 'tcp_connect' type_id=26236 linkage=static
[72694] FUNC_PROTO '(anon)' ret_type_id=920 vlen=6
'sk' type_id=2954
然后通过 id, 找到其函数返回值类型 id = 28, 参数 id = 768
$ bpftool btf dump id 1 | grep -A 2 "\[26236]"
[26236] FUNC_PROTO '(anon)' ret_type_id=28 vlen=1
'sk' type_id=768
继续通过 id, 找到返回值类型是 int, 参数类型 sock
$ bpftool btf dump id 1 | grep -A 2 "\[768]"
[768] PTR '(anon)' type_id=769
[769] STRUCT 'sock' size=776 vlen=94
'__sk_common' type_id=2905 bits_offset=0
$ bpftool btf dump id 1 | grep -A 10 "\[768]"
[768] PTR '(anon)' type_id=769
[769] STRUCT 'sock' size=776 vlen=94
'__sk_common' type_id=2905 bits_offset=0
'sk_rx_dst' type_id=2075 bits_offset=1088
'sk_rx_dst_ifindex' type_id=28 bits_offset=1152
'sk_rx_dst_cookie' type_id=42 bits_offset=1184
'sk_lock' type_id=2890 bits_offset=1216
'sk_drops' type_id=93 bits_offset=1472
'sk_rcvlowat' type_id=28 bits_offset=1504
'sk_error_queue' type_id=2281 bits_offset=1536
'sk_receive_queue' type_id=2281 bits_offset=1728
借助 BTF 信息, 我们可以编译出自动适配不同内核版本的 eBPF 程序
struct sock *sk = (struct sock *)PT_REGS_PARM1(ctx);
u16 family = BPF_CORE_READ(sk, sk_family);
而 bpfsnoop 过系统调用获取这些 BTF 信息, 有了这些信息,bpfsnoop 可以在运行时动态解析任何内核函数的签名。
// internal/btfx/btf.go
func LoadKernelBTF() (*btf.Spec, error) {
// 尝试从 /sys/kernel/btf/vmlinux 读取
if btfSpec, err := btf.LoadKernelSpec(); err == nil {
return btfSpec, nil
}
// 回退到从内核映像文件读取
return btf.LoadSpecFromFile("/boot/vmlinux")
}
bpfsnoop 实现分析
文件架构
(bpfsnoop)[https://bpfsnoop.com] 采用经典的用户态Go + 内核态C的文件组织结构, 下面是其文件分布:
┌────────────────────────────────────────────────────────────────────────────┐
│ │
│ User Space: Kernel Space: │
│ ├── cmd/bpfsnoop/ ├── bpf/bpfsnoop.c │
│ │ ├── main.go │ ├── bpfsnoop_fn template │
│ │ └── flags.go │ ├── output_arg stub │
│ ├── internal/bpfsnoop/ │ └── filter_arg stub │
│ │ ├── tracer.go └── Generated at runtime: │
│ │ ├── bpf_manager.go ├── fentry programs │
│ │ ├── output_arg.go ├── fexit programs │
│ │ ├── bpf_asm.go └── injected instructions │
│ │ └── event_processor.go │
│ ├── internal/btfx/ │
│ │ ├── btf.go │
│ │ └── types.go │
│ └── internal/cc/ │
│ ├── compiler.go │
│ └── parser.go │
└────────────────────────────────────────────────────────────────────────────┘
运行过程解析
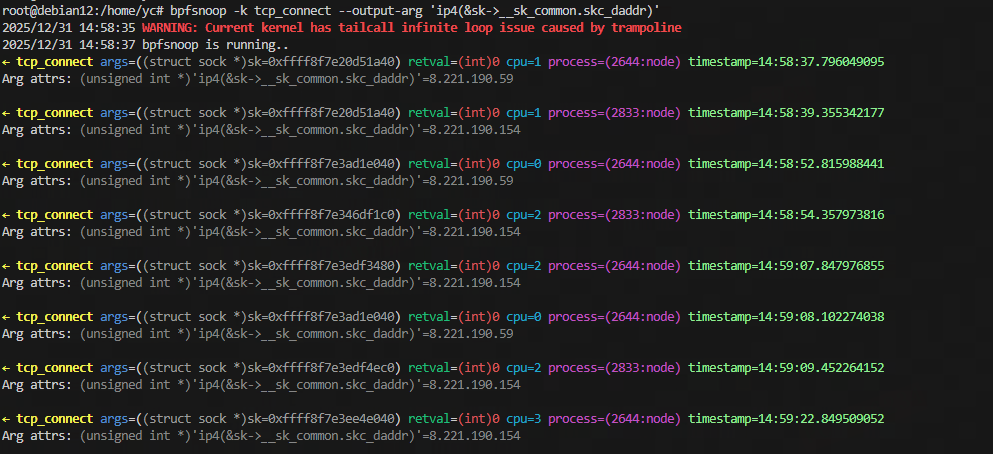
下面以一个具体的例子展示程序是如何运行的: attach 到 tcp_connect 上, 打印主机对外发起的 TCP 连接的地址.
输入的命令是
bpfsnoop -k tcp_connect --output-arg 'ip4(&sk->__sk_common.skc_daddr)'
整个运行过程大概分为以下几个阶段:
- 命令解析
- 内核环境检测和准备
- 内核符号信息加载
- 加载 BPF 程序模板
- 查找目标内核函数
- 检测目标的可跟踪性
- 编译注入加载 BPF 程序
- 数据输出
命令解析
这是整个程序的入口, 程序解析我们的输入。
// main.go
flags, err := bpfsnoop.ParseFlags()
解析完成后 flags 将存储我们的输入
type Flags struct {
kfuncs []string // [tcp_connect]
outputArgs []string // [ip4(&sk->__sk_common.skc_daddr)]
// ... 其他配置项
}
内核环境检测和准备
err = rlimit.RemoveMemlock() // 移除内存锁限制
err = bpfsnoop.PrepareKernelBTF() // 准备内核BTF信息
err = bpfsnoop.DetectBPFFeatures() // 检测BPF特性
内核符号信息加载
这里将读取内核符号表
bpfsnoop.VerboseLog("Reading /proc/kallsyms ..")
kallsyms, err := bpfsnoop.NewKallsyms()
assert.NoErr(err, "Failed to read /proc/kallsyms: %v")
其中
type Kallsyms struct {
symbols map[string]uint64 // 函数名 -> 内核地址
stext uint64 // _stext 地址(内核代码段开始)
}
加载 BPF 程序模板
bpfSpec, err := bpf.LoadBpfsnoop()
assert.NoErr(err, "Failed to load bpf spec: %v")
bpfsnoop 并不需要用户提供 BPF 程序, 而是内置一个通用的 bpf 程序模板, 在运行时动态将指令注入该 BPF 程序
下面这是预编译的 BPF 程序模板
// 对应 bpf/bpfsnoop.c 中的模板程序
SEC("fexit")
int BPF_PROG(bpfsnoop_fn)
{
return emit_bpfsnoop_event(ctx);
}
emit_bpfsnoop_event的功能总结为 “生成空白event->填充event->写入ringbuf”
查找目标内核函数
接下来, 程序从之前读取的内核符号中搜索我们的输入中制定 tcp_connect
kfuncs, err := bpfsnoop.FindKernelFuncs(flags.Kfuncs(), kallsyms, maxArg)
assert.NoErr(err, "Failed to find kernel functions: %v")
检测目标的可跟踪性
bpfsnoop 默认使用 fentry/fexit (BPF Trampoline) 对函数进行 attach. 如果这个内核函数不能以 fentry/fexit 的方式被 attach, 则会回退到 tracepoint 或者 kprobe.
不过这点不用太过担心, 大部分内核函数都支持 fentry/fexit.
编译注入加载 BPF 程序
NewBPFTracing是 bpfsnoop 中最重要的函数之一,负责协调所有类型的 BPF 程序的编译、注入和加载过程.
tracings, err := bpfsnoop.NewBPFTracing(bpfSpec, reusedMaps, bpfProgs, kfuncs, insns, graphs)
接下来深入NewBPFTracing, 对我们来说, 核心是指定内核函数进行跟踪
t.traceFuncs(&errg, spec, reusedMaps, kfuncs)
展开 traceFuncs, 会对每个要跟踪的函数异步调用traceFunc
接下来进入traceFunc, 这是 bpfsnoop 中最核心的函数, 负责为单个内核函数完成完整的 BPF 程序编译、注入和 attach 流程.
func (t *bpfTracing) traceFunc(
spec *ebpf.CollectionSpec, // BPF 程序集合模板
reusedMaps map[string]*ebpf.Map, // 共享的 BPF Maps
fn *KFunc, // 要追踪的内核函数信息
bothEntryExit bool, // 是否同时追踪入口和出口
isExit bool, // 当前是否为出口追踪
stack bool, // 是否输出调用栈
) error
这里先取出模板 bpf 程序的 Spec 以及要跟踪的函数名字:
tracingFuncName := TracingProgName() // 获取 BPF 程序名称:"bpfsnoop_fn"
traceeName := fn.Func.Name // 内核函数名:"tcp_connect"
progSpec := spec.Programs[tracingFuncName] // 获取 BPF 程序规格
funcProto := fn.Func.Type.(*btf.FuncProto) // 获取函数原型
params := funcProto.Params // 获取函数参数列表
随后先后经过 包输出注入 / 包过滤注入 / 参数过滤注入 / 参数输出注入, 对应命令行参数 --output-pkt / --filter-pkt / --filter-arg / --output-arg
由于我们只输入了 --output-arg, 因此只关注参数输出注入的过程
args, argDataSize, err := t.injectArgOutput(progSpec, params, fn.Btf, traceeName)
injectArgOutput将用户通过 –output-arg 选项指定的表达式注入到 BPF 模板程序中 (emit_bpfsnoop_event中的output_fn_args)
关于指令注入, 请参考TODO.
随后, bpfsnoop 将注入后 BPF 程序 attach 到内核 tcp_connect
prog := coll.Programs[tracingFuncName]
delete(coll.Programs, tracingFuncName)
l, err := link.AttachTracing(link.TracingOptions{
Program: prog,
AttachType: attachType,
})
数据输出
当内核tcp_connect被调用时, 执行被注入的 BPF 程序, 将我们关心的参数发送到 bpfsnoop_events, 用户态即可从中读取并输出
运行效果